Advanced Chinese Hamster Ovary (CHO) Cell Kinetic Modeling: A Comprehensive Guide to Validation, Application, and Optimization for Biopharmaceutical Development
This comprehensive article explores the critical process of validating kinetic models for Chinese Hamster Ovary (CHO) cells, the predominant host system for therapeutic protein production.
Advanced Chinese Hamster Ovary (CHO) Cell Kinetic Modeling: A Comprehensive Guide to Validation, Application, and Optimization for Biopharmaceutical Development
Abstract
This comprehensive article explores the critical process of validating kinetic models for Chinese Hamster Ovary (CHO) cells, the predominant host system for therapeutic protein production. It begins by establishing the foundational principles and key model types (mechanistic, metabolic flux analysis, constraint-based) and their role in bioprocess digital twins. The methodological section details the practical application of parameter estimation, sensitivity analysis, and experimental design for in silico bioprocess development. Common challenges such as identifiability issues, data scarcity, and model overfitting are addressed with robust troubleshooting strategies. Finally, the article provides a framework for rigorous model validation through statistical methods, cross-validation, and comparative benchmarking against experimental data. Aimed at researchers and process development professionals, this guide synthesizes current best practices to enhance model reliability, accelerate biopharmaceutical development, and support Quality by Design (QbD) initiatives.
Understanding CHO Cell Kinetics: The Core Principles and Types of Models for Bioprocess Prediction
The Central Role of CHO Cells in Modern Biomanufacturing and the Need for Predictive Models
CHO cells are the predominant mammalian host for therapeutic protein production. This guide compares their performance against alternative expression systems, focusing on kinetic model development for bioprocess optimization.
Comparison Guide: Expression Systems for Therapeutic Protein Production
Table 1: Comparative Performance of Major Expression Systems
| Parameter | CHO Cells | HEK293 Cells | Yeast (P. pastoris) | Insect Cells (Sf9) |
|---|---|---|---|---|
| Typical Titers (g/L) | 3-10 | 0.5-3 | 1-10 | 0.1-1 |
| Glycosylation Profile | Complex, human-like (with variations) | Complex, human-like | High-mannose, non-human | Simple, paucimannosidic |
| Post-Translational Modification Fidelity | High | High | Low | Moderate |
| Growth Rate (Doubling Time) | 20-36 hours | 18-30 hours | 2-4 hours | 18-24 hours |
| Cost & Process Scalability | High cost, highly scalable | Very high cost, moderately scalable | Low cost, highly scalable | Moderate cost, scalable |
| Key Model Development Challenge | Metabolic complexity & heterogeneity | Transient expression kinetics | Overflow metabolism & induction dynamics | Baculovirus infection kinetics |
Supporting Experimental Data from Kinetic Model Validation Studies
Experiment 1: Comparison of metabolic flux predictions vs. measured extracellular metabolite rates in fed-batch cultures.
- Protocol: A GS-CHO cell line producing a monoclonal antibody was cultured in a 5L bioreactor. Daily samples were taken for cell count, viability, and metabolite (glucose, lactate, glutamine, ammonia, amino acids) concentration. A genome-scale metabolic model (GSMM) was constrained with measured uptake/secretion rates. Flux Balance Analysis (FBA) was performed to predict intracellular flux distributions at 24, 72, and 120 hours.
- Results: The model successfully predicted the metabolic shift from lactate production to consumption (lactate switch) but under-predicted ammonia production in later stages, indicating missing regulatory constraints.
Table 2: Predicted vs. Measured Metabolic Fluxes at 72h Culture
| Metabolic Flux | Model Prediction (mmol/10^9 cells/day) | Experimental Measurement (mmol/10^9 cells/day) | Deviation |
|---|---|---|---|
| Glucose Uptake | 1.25 | 1.28 | -2.3% |
| Lactate Production | 0.08 | 0.05 | +60.0% |
| Glutamine Uptake | 0.32 | 0.35 | -8.6% |
| Ammonia Production | 0.41 | 0.58 | -29.3% |
Experiment 2: Comparison of cell growth and product titer predictions between a simple Monod-based model and a dynamic multi-scale model.
- Protocol: Two models were calibrated with data from a 2L fed-batch run. The Simple Model used Monod kinetics for growth with glucose and glutamine limitation. The Multi-Scale Model integrated central metabolism, cell cycle phases, and ER protein folding kinetics. Both models were used to predict outcomes of a new feeding strategy with shifted nutrient concentrations.
- Results: The multi-scale model more accurately predicted the delayed VCD peak and final titer under the new feeding regime.
Table 3: Model Prediction Accuracy for a Novel Feeding Strategy
| Output Variable | Simple Model Error | Multi-Scale Model Error | Experimental Result |
|---|---|---|---|
| Peak VCD (10^6 cells/mL) | +22.5% | +4.8% | 12.5 |
| Final Titer (g/L) | -18.2% | -5.1% | 4.7 |
| Culture Duration (days) | -2 days | +0.5 days | 14 days |
Visualizations
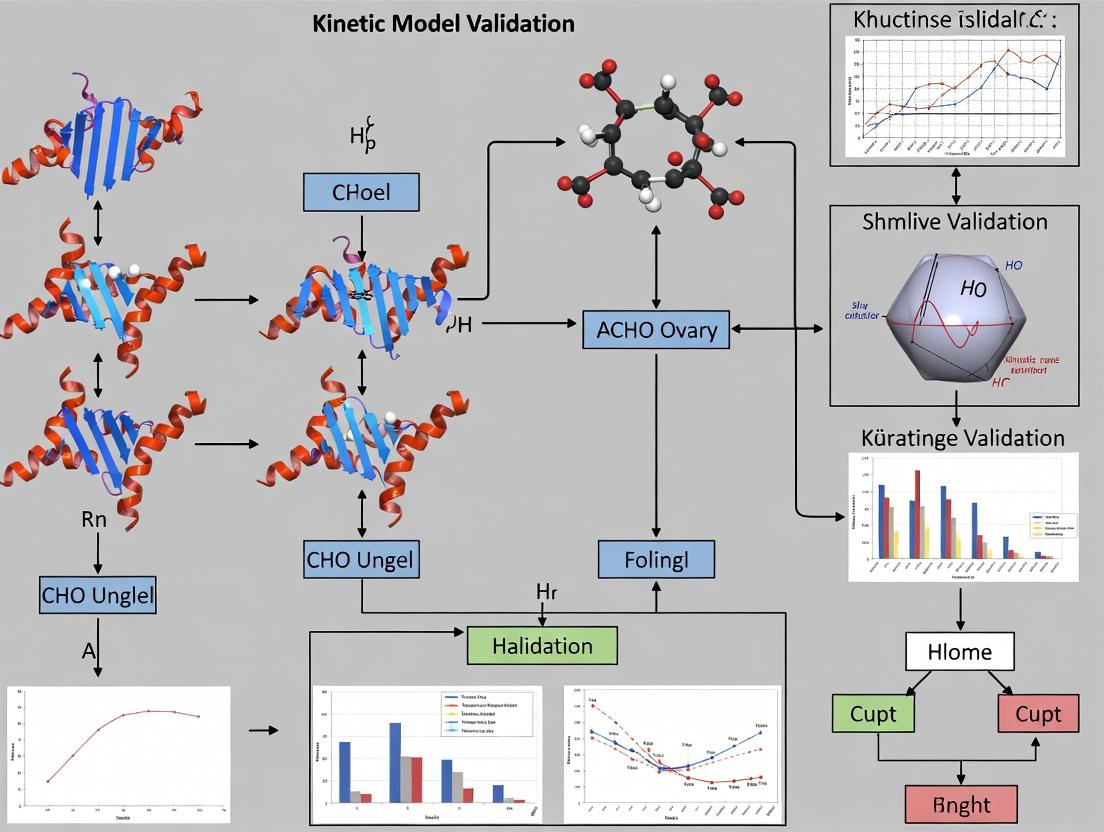
CHO Cell Kinetic Model Validation & Application Workflow
Simplified CHO Cell Central Metabolism & Product Synthesis Pathway
The Scientist's Toolkit: Key Research Reagents for CHO Model Validation
Table 4: Essential Reagents and Materials for CHO Kinetic Studies
| Reagent/Material | Function in Model Validation |
|---|---|
| Chemically Defined Media | Provides a consistent, animal-component-free basal medium for reproducible metabolic studies. |
| Custom Feed Supplements | Allows precise perturbation of nutrient concentrations to challenge and validate model predictions. |
| Extracellular Metabolite Kits (e.g., Bioprofile Analyzer reagents) | Enables high-frequency measurement of glucose, lactate, glutamine, ammonia, and amino acids for flux calculation. |
| Live Cell Analysis Instrument (e.g., Cedex HiRes, NucleoCounter) | Provides accurate time-series data on viable cell density (VCD) and viability, critical for growth kinetic models. |
| mRNA Sequencing Kits | Enables transcriptomic profiling to inform regulation in gene expression models (e.g., GEMs). |
| Titer Measurement Assays (e.g., Protein A HPLC, Octet) | Quantifies therapeutic protein concentration, the ultimate output variable for productivity models. |
| Stable Isotope Tracers (¹³C-Glucose/Glutamine) | Used in advanced fluxomics studies to map intracellular pathway activity and validate metabolic models. |
| Process Control Software (e.g., DASware, BioPAT MFCS) | Records all process parameters (pH, DO, feeding rates) essential for integrating physical models with kinetic models. |
This guide is framed within ongoing research validating kinetic models for Chinese Hamster Ovary (CHO) cells, the predominant host for therapeutic protein production. Understanding the intricate relationships between cell growth, metabolism, nutrient utilization, and product formation is critical for optimizing bioprocesses. This comparison guide evaluates key methodologies and technologies used to quantify these kinetic parameters, providing a framework for researchers to select appropriate tools for model validation and process development.
Comparison of Key Analytical Platforms for Cell Kinetics
Table 1: Comparison of Major Technologies for Metabolic Flux Analysis
| Technology / Method | Measured Parameters | Throughput | Approx. Cost per Sample | Key Advantage | Primary Limitation |
|---|---|---|---|---|---|
| Extracellular Flux Analyzer (e.g., Seahorse XF) | Glycolytic Rate, Oxygen Consumption Rate (OCR), ATP Production Rate | Medium (20-40 samples/run) | $80 - $120 | Real-time, live-cell kinetic measurements in microplates. | Measures only extracellular acidification and O2; limited to adherent cells or spheroids. |
| Nuclear Magnetic Resonance (NMR) Spectroscopy | Real-time intracellular metabolite concentrations (e.g., ATP, glucose, lactate), metabolic fluxes. | Low | $300 - $500+ | Non-destructive; provides atomic-level structural and quantitative data. | Low sensitivity; requires high cell numbers or concentrated samples. |
| Liquid Chromatography-Mass Spectrometry (LC-MS) | Comprehensive intracellular/extracellular metabolome, isotope tracing (13C, 15N). | Medium-High | $150 - $300 | High sensitivity and breadth of metabolite coverage. | Destructive sampling; complex data analysis; non-real-time. |
| In-line Raman Spectroscopy | Real-time concentration of glucose, lactate, glutamate, product titer, cell density. | Continuous | High capital cost | Non-invasive, in-line process monitoring enabling real-time control. | Requires complex chemometric models for calibration; overlapping spectral features. |
| Enzyme-Linked Immunosorbent Assay (ELISA) | Specific protein product concentration, growth factor levels. | High (96-well format) | $20 - $50 | Highly specific and sensitive for target proteins. | Measures only a single analyte; endpoint assay only. |
Table 2: Comparison of Kinetic Models for CHO Cell Processes
| Model Type | Key Inputs Required | Typical Outputs | Validation Complexity | Best Suited For |
|---|---|---|---|---|
| Unstructured, Non-Segregated (e.g., Monod) | Extracellular nutrient (Glc, Gln) and metabolite (Lac, Amm) concentrations. | Growth rate (μ), substrate consumption rates, product formation rates. | Low | Early-stage process characterization and simple dynamic simulations. |
| Metabolic Flux Analysis (MFA) | Extracellular uptake/secretion rates, optionally 13C labeling data. | Intracellular metabolic flux map (mmol/gDCW/h), network energy/redox balances. | Medium | Identifying metabolic bottlenecks and engineering targets. |
| Mechanistic Dynamic (e.g., Cybernetic) | Time-series data for cells, substrates, products, inhibitors. | Predictions of metabolic shift (e.g., lactate shift), progression through metabolic states. | High | Predicting fed-batch dynamics and complex metabolic transitions. |
| Hybrid Machine Learning (ML) / Physicochemical | Multi-omics data (transcriptomics, fluxomics) and process parameters. | Enhanced predictions of cell growth and product titer under novel conditions. | Very High | Digital twin development and advanced process control. |
Experimental Protocols for Key Kinetic Studies
Protocol 1: Real-Time Metabolic Flux Analysis using a Seahorse XF Analyzer
Objective: To measure the glycolytic rate and mitochondrial respiration of CHO cells in real-time under different nutrient conditions.
- Cell Preparation: Seed CHO cells in a specialized 8-well microplate (Agilent) at 2-4 x 10^5 cells/well. Centrifuge sensor cartridge in calibration solution overnight.
- Assay Medium: Replace growth medium with assay medium (XF base, 10 mM glucose, 2 mM glutamine, 1 mM pyruvate, pH 7.4). Incubate for 1 hr at 37°C, non-CO2.
- Sensor Cartridge Loading: Inject metabolic modulators into cartridge ports (e.g., Port A: 10X glucose for glycolysis stress test).
- Run Assay: Insert cartridge into XF Analyzer. The protocol sequentially measures:
- Basal OCR and Extracellular Acidification Rate (ECAR).
- Post-injection measurements after glucose (glycolysis), oligomycin (ATP-linked respiration), and rotenone/antimycin A (non-mitochondrial respiration).
- Data Analysis: Calculate key parameters: Glycolytic Rate, Glycolytic Capacity, ATP Production Rate, Spare Respiratory Capacity using Wave software.
Protocol 2: 13C Metabolic Flux Analysis (13C-MFA) using LC-MS
Objective: To quantify intracellular metabolic flux distributions in central carbon metabolism.
- Isotope Tracer Experiment: Grow CHO cells in a controlled bioreactor. Switch feed to media containing 13C-labeled glucose (e.g., [U-13C]glucose) or glutamine.
- Quenching and Extraction: At metabolic steady-state, rapidly sample culture and quench metabolism (cold methanol/water solution). Lyse cells and extract intracellular metabolites.
- LC-MS Analysis: Separate metabolites via hydrophilic interaction liquid chromatography (HILIC). Analyze using high-resolution mass spectrometer to detect mass isotopomer distributions (MIDs) of metabolites (e.g., glycolytic intermediates, TCA cycle acids).
- Flux Calculation: Use software (e.g., INCA, OpenFlux) to fit a stoichiometric metabolic network model to the measured MIDs and extracellular rates, estimating net intracellular fluxes that best explain the labeling data.
Diagram: CHO Cell Kinetic Pathways and Analysis
Title: Integration of CHO Cell Kinetics with Analytical Methods
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Reagents for CHO Cell Kinetic Studies
| Item | Function in Kinetic Research | Example Product/Brand |
|---|---|---|
| CD CHO Medium | Chemically defined, animal-component-free basal medium for consistent growth and metabolism studies. | Gibco CD CHO, EX-CELL Advanced CHO |
| 13C-Labeled Glucose/Glutamine | Tracer substrates for Metabolic Flux Analysis (MFA) to elucidate intracellular pathway fluxes. | Cambridge Isotope Laboratories [U-13C]Glucose |
| Extracellular Flux Assay Kits | Pre-optimized reagent packs for measuring oxygen consumption and glycolysis in live cells. | Agilent Seahorse XF Glycolysis Stress Test Kit |
| Recombinant Insulin / Lipids | Key supplement components affecting metabolic shifts and cell growth kinetics. | Chemically Defined Lipid Mixture, Human Recombinant Insulin |
| L-Glutamine / GlutaMAX | Essential amino acid and energy source; GlutaMAX is a stable dipeptide alternative. | Gibco GlutaMAX Supplement |
| Anti-apoptosis Agents | Supplements to reduce cell death, clarifying growth kinetics unrelated to apoptosis. | MilliporeSigma Viability Supplement (Anti-Clusterin) |
| Peptone / Protein Hydrolysates | Complex additives used to boost cell growth and productivity in fed-batch studies. | HyPep Soy Hydrolysate, Ultramone |
| Metabolite Assay Kits (Colorimetric) | For rapid, specific quantification of glucose, lactate, ammonium, etc., from culture supernatant. | BioVision Lactate Assay Kit, R-Biopharm Enzymatic BioAnalysis |
| Rapid Sampling Devices | Enables fast quenching of metabolism for accurate intracellular metabolite measurement. | Fast-Filtration Manifolds, Cold Methanol Quenching Systems |
This guide provides a comparative analysis of kinetic model frameworks for CHO cell culture, a cornerstone of biotherapeutic production. Within the broader context of thesis research on CHO cell kinetic model validation, we evaluate these frameworks' performance in predicting critical process outcomes like cell growth, metabolite consumption, and recombinant protein production.
Framework Definitions & Core Comparison
Kinetic models mathematically describe the rates of cellular processes. Their formulation directly impacts predictive capability and utility in process development.
Table 1: Core Characteristics of Kinetic Model Frameworks
| Framework Category | Description | Key Advantages | Key Limitations | Typical Application in CHO Processes |
|---|---|---|---|---|
| Unstructured | Treats the cell population as a homogeneous unit. Ignores internal cell composition. | Simple, requires fewer parameters, easier to fit to data. | Cannot predict effects of metabolic shifts or cell cycle on productivity. | High-level process screening, initial growth and substrate consumption models. |
| Structured | Accounts for intracellular composition by dividing biomass into key compartments (e.g., machinery, storage). | Can predict intracellular state changes, more robust for dynamic conditions. | Higher complexity, more parameters requiring extensive experimental data for identification. | Media optimization, studying nutrient limitation effects, feeding strategy design. |
| Mechanistic (Bottom-Up) | Based on fundamental biochemical and physiological principles (e.g., Michaelis-Menten, Monod kinetics). | Strong predictive power extrapolation, biologically interpretable parameters. | Development is time-intensive; requires deep prior knowledge of the system. | Detailed process understanding, root-cause analysis of process deviations. |
| Hybrid (Semi-Mechanistic) | Combines mechanistic elements with data-driven functions (e.g., artificial neural networks, black-box kinetics). | Balances biological insight with flexibility; can model complex, poorly understood interactions. | Risk of overfitting; some parameters may lose biological meaning. | Modeling complex phenomena like apoptosis dynamics or product quality attributes (glycosylation). |
Experimental Performance Comparison
Recent studies have systematically compared these frameworks. The following data is synthesized from published validation experiments using CHO-S cells producing a monoclonal antibody (mAb) in fed-batch bioreactors.
Table 2: Model Performance in Predicting Fed-Batch CHO Culture Outcomes
| Model Type (Example) | Key Model Equations | Fitted Parameters | Avg. Error (Viable Cell Density) | Avg. Error (Titer) | Ability to Predict Lactate Shift* |
|---|---|---|---|---|---|
| Unstructured (Monod-based) | ( \mu = \mu{max} \frac{[Glc]}{Ks + [Glc]} ) | (\mu{max}), (Ks), (Y_{x/glc}) | 12-18% | 20-25% | No |
| Structured (2-Compartment) | Separate balances for growth & machinery; (\mu = k_{syn} \cdot [Ribosome]) | (k{syn}), (k{deg}), partitioning coefficients | 8-12% | 15-20% | Partial |
| Mechanistic (Dynamic Metabolic) | Includes ATP balances, overflow metabolism kinetics: ( q{Lac} = f(q{Glc}, [ATP]) ) | Multiple kinetic constants for glycolysis/TCA | 5-10% | 10-15% | Yes |
| Hybrid (ANN-Augmented) | Mechanistic growth + Neural Network for ( q_{Mab} = ANN([Metabolites]) ) | Mech. params + ANN weights | 4-8% | 8-12% | Yes |
*Lactate shift: The transition from net lactate production to consumption observed in optimized processes.
- Cell Line & Culture: CHO-DG44 cells expressing an IgG1 mAb are cultivated in a chemically defined medium in 2L bench-scale bioreactors (n=3 per condition).
- Fed-Batch Design: A standard industrial feeding strategy is employed, with perturbations in initial glucose and glutamine levels to challenge the models.
- Data Collection: Daily samples analyze viable cell density (VCD), viability (via trypan blue), and metabolite concentrations (Glc, Gln, Lac, Amm, amino acids) via bioanalyzer. Titer is measured daily by Protein A HPLC.
- Parameter Estimation: Model parameters are estimated from a "training" set of bioreactors using non-linear regression or genetic algorithms, minimizing the sum of squared errors between model predictions and experimental data for VCD, Glc, Lac, and Titer.
- Validation: The calibrated models are used to predict the outcomes of the perturbed cultures not used in training. Performance is quantified using metrics like Root Mean Square Error (RMSE) and Normalized RMSE.
Visualizing Model Structures and Workflow
Title: Conceptual Structure of Four Kinetic Model Frameworks
Title: Workflow for Kinetic Model Development and Validation
The Scientist's Toolkit: Key Research Reagent Solutions
Table 3: Essential Materials for CHO Kinetic Model Validation Experiments
| Item & Example Product | Function in Model Validation |
|---|---|
| Chemically Defined Basal & Feed Media (e.g., Gibco ActiPro, Thermo Fisher) | Provides a consistent, animal-component-free environment essential for reproducible data and identifiable model parameters. |
| Metabolite Assay Kits (e.g., BioProfile FLEX2 Analyzer reagents, Nova Biomedical) | Enables high-frequency, accurate measurement of glucose, lactate, glutamine, ammonia, and other key metabolites for kinetic rate calculations. |
| Cell Count & Viability Reagents (e.g., Trypan Blue Solution, Gibco) | The gold standard for determining viable cell density (VCD) and viability, the primary state variables for most models. |
| Product Titer Assay Kits (e.g., MabSelect Protein A sensors on Octet or HPLC columns) | Quantifies recombinant protein concentration over time, the critical quality output for model prediction. |
| Amino Acid Analysis Kits (e.g., AccQ•Tag Ultra for UPLC, Waters) | Provides detailed amino acid consumption/production profiles needed for advanced structured and mechanistic models. |
| Process Control Software & Bioreactors (e.g., DASware control with DasGip or Applikon bioreactors) | Allows for precise environmental control (pH, DO, temperature) and automated data logging, ensuring high-quality input data for models. |
Metabolic modeling is a cornerstone of systems biology, enabling the quantitative analysis of cellular metabolism. Two predominant approaches are Flux Balance Analysis (FBA), a constraint-based stoichiometric model, and Kinetic Metabolic Modeling, a dynamic, mechanism-driven framework. This guide objectively compares their performance, applications, and validation within the critical context of Chinese Hamster Ovary (CHO) cell bioprocessing for therapeutic protein production.
Core Conceptual Comparison
Flux Balance Analysis (FBA) is a static, genome-scale modeling approach. It calculates steady-state reaction fluxes by optimizing an objective function (e.g., biomass or product formation) subject to mass-balance and capacity constraints. It requires a stoichiometric matrix and exchange bounds but not kinetic parameters.
Kinetic Metabolic Modeling employs detailed enzyme kinetics (Michaelis-Menten constants, inhibition coefficients) to simulate the dynamic, time-dependent behavior of metabolite concentrations and reaction fluxes. It captures system responses to perturbations more realistically but demands extensive parameterization.
Performance Comparison: Application in CHO Cell Culture Optimization
The table below summarizes a comparative analysis based on recent research for optimizing CHO cell cultures.
Table 1: Comparative Performance of FBA vs. Kinetic Models in CHO Cell Applications
| Feature / Metric | Flux Balance Analysis (FBA) | Kinetic Metabolic Modeling |
|---|---|---|
| Model Scope | Genome-scale (thousands of reactions) | Small to medium-scale pathways (dozens to hundreds of reactions) |
| Data Requirements | Stoichiometry, uptake/secretion rates, growth rate. | Enzyme kinetic parameters (Km, Vmax), initial metabolite conc., inhibitor constants. |
| Computational Demand | Low (Linear Programming) | High (Systems of ODEs, requires numerical integration) |
| Primary Output | Steady-state flux distribution | Time-course of metabolite concentrations and fluxes |
| Predictive Capability | Predicts optimal yields and knockout strategies. Limited to steady-state. | Predicts transient responses to perturbations, pathway dynamics, and control. |
| Parameter Identifiability | High (few parameters relative to constraints) | Challenging (many parameters, often underdetermined) |
| CHO Cell Case Study Outcome | Accurately predicted increased monoclonal antibody (mAb) yield (∼15%) after gene knockout simulations validated experimentally. | Successfully modeled lactate shift (production to consumption) dynamics, predicting optimal feed timing, improving cell density by ∼22%. |
| Key Validation Metric | Correlation between predicted vs. measured growth rates (R² = 0.78-0.91). | RMSE of simulated vs. experimental metabolite time-courses (e.g., Glc, Lac, Gln < 10%). |
| Major Limitation | Cannot predict metabolite concentrations or transients. | Scalability and comprehensive parameter estimation are significant hurdles. |
Experimental Protocols for Model Validation in CHO Cells
Protocol 1: FBA Model Validation via ({}^{13})C-Metabolic Flux Analysis (({}^{13})C-MFA)
Objective: Validate genome-scale FBA-predicted intracellular fluxes in a CHO cell culture.
- Culture: Grow CHO cells in a controlled bioreactor in fed-batch mode.
- Tracer Experiment: At mid-exponential phase, introduce [1-({}^{13})C]glucose into the medium.
- Sampling: Harvest cells at isotopic steady-state (∼24h). Quench metabolism rapidly, extract intracellular metabolites.
- Mass Spectrometry (MS): Analyze proteinogenic amino acids and central carbon metabolites via GC-MS or LC-MS to determine ({}^{13})C labeling patterns.
- Flux Calculation: Use software (e.g., INCA, OpenFLUX) to compute metabolic fluxes that best fit the measured mass isotopomer distributions.
- Validation: Compare the experimentally determined fluxes from ({}^{13})C-MFA with the FBA-predicted flux distributions.
Protocol 2: Kinetic Model Validation via Dynamic Metabolite Profiling
Objective: Calibrate and validate a kinetic model of central carbon metabolism.
- Perturbation Experiment: Cultivate CHO cells in a bioreactor. At a defined time, introduce a bolus of glucose or shift culture pH.
- High-Frequency Sampling: Automatically sample culture broth every 30-60 seconds immediately post-perturbation for 30 minutes, then at decreasing frequency for 24h.
- Rapid Metabolomics: Use targeted LC-MS/MS to quantify key extracellular (glucose, lactate, ammonia) and intracellular (G6P, PEP, ATP) metabolite concentrations.
- Parameter Estimation: Use the initial post-perturbation data to estimate uncertain kinetic parameters via model fitting algorithms (e.g., particle swarm optimization).
- Predictive Validation: Use the calibrated model to simulate a different perturbation (e.g., glutamine pulse) not used for fitting. Compare model predictions against new experimental data.
Model Development and Validation Workflow
Title: Workflow for Developing and Validating FBA and Kinetic Metabolic Models
The Scientist's Toolkit: Research Reagent Solutions for CHO Model Validation
Table 2: Essential Reagents and Materials for Metabolic Model Validation Experiments
| Item | Function in Validation | Example / Specification |
|---|---|---|
| Stable Isotope Tracers | Enables ({}^{13})C-MFA for flux validation. | [1-({}^{13})C]Glucose, [U-({}^{13})C]Glutamine (>99% isotopic purity). |
| Rapid Sampling Device | Quenches metabolism in <1 second for accurate snapshots of intracellular states. | Cold methanol quenching system or automated syringe-based bioreactor sampler. |
| Targeted Metabolomics Kits | Quantifies absolute concentrations of key metabolites for kinetic model calibration/validation. | LC-MS/MS kits for Central Carbon Metabolism, Nucleotides, Co-factors. |
| Chemically Defined Media | Provides a precisely known stoichiometric input for FBA constraint setting. | Commercial CHO CD media, optionally custom-formulated. |
| Enzyme Activity Assay Kits | Measures Vmax for key enzymes (e.g., HK, LDH) to inform kinetic model parameters. | Colorimetric or fluorometric assays for cell lysates. |
| Metabolic Inhibitors/Modulators | Creates controlled perturbations to test model predictions. | 2-DG (glycolysis inhibitor), UK5099 (mitochondrial pyruvate carrier inhibitor). |
| Process Monitoring Sensors | Provides real-time data for constraints (FBA) or inputs (Kinetic). | Bioreactor probes for DO, pH, biomass (via capacitance). |
| Modeling Software | Platform for building, simulating, and fitting models. | FBA: COBRApy, CellNetAnalyzer. Kinetic: Copasi, PySCeS, MATLAB/SimBiology. MFA: INCA, IsoSim. |
The Concept of Bioprocess Digital Twins and the Central Role of Validated Kinetic Models
Digital Twins (DTs) are virtual replicas of physical bioprocessing systems that simulate, predict, and optimize process outcomes in real-time. For Chinese Hamster Ovary (CHO) cell-based bioproduction, the core of an effective DT is a rigorously validated kinetic model. This model mathematically describes cell growth, metabolism, nutrient consumption, and product formation. Without validation against experimental data, a model remains a theoretical construct; validation transforms it into a credible predictive tool, forming the central decision-making engine of the digital twin.
Comparison Guide: Kinetic Model Frameworks for CHO Cell Digital Twins
The performance of a CHO cell digital twin is directly dependent on the underlying kinetic modeling framework. The table below compares three prevalent approaches.
Table 1: Comparison of Kinetic Modeling Frameworks for CHO Cell Culture
| Framework Type | Core Methodology | Key Advantages for Digital Twin | Key Limitations | Example Experimental Support (Recent Findings) |
|---|---|---|---|---|
| Unstructured, Segregated | Uses ordinary differential equations (ODEs) for bulk metrics (e.g., total viable cells, metabolites). Considers cell population heterogeneity. | Computationally efficient; suitable for real-time control; parameters are relatively identifiable. | Limited mechanistic insight; may not extrapolate well to new process conditions. | Zhang et al. (2023) showed a validated glutamine/ammonia metabolism model reduced lactate accumulation by 40% in fed-batch, increasing titer by 22% vs. model-free control. |
| Cybernetic / Hybrid | Combines simplified metabolic network (e.g., 4-5 key pathways) with control rules regulating enzyme synthesis/activity. | Captures metabolic shifts (e.g., lactate transition); more predictive across phases than pure unstructured models. | Increased complexity; requires careful parameter estimation for cybernetic variables. | A 2024 study integrated a cybernetic model with online Raman data, predicting IgG titer at day 10 within ±12% error from day 5, enabling earlier feed adjustments. |
| Mechanistic, Genome-Scale Model (GSM)-Informed | Constrains a reduced metabolic network with omics data (transcriptomics, fluxomics) from CHO cells. | High mechanistic fidelity; potential for cell line and clone-specific digital twins. | Extremely data-intensive; computationally heavy; not yet practical for real-time application. | Research by Sellick et al. (2024) demonstrated that a GSM-informed kinetic model correctly predicted the 15% titer drop caused by a specific media component limitation, which was experimentally confirmed. |
Detailed Experimental Protocol for Kinetic Model Validation
The following protocol is central to thesis research on building a validated model for a CHO-DG44 cell line producing a monoclonal antibody.
Title: Integrated Workflow for Kinetic Model Calibration and Validation in Fed-Batch Bioreactors
Objective: To generate high-quality, multi-parameter time-course data for calibrating (parameter estimation) and independently validating a structured kinetic model of CHO cell culture.
Methodology:
- Bioreactor Setup: Perform triplicate 2L fed-batch bioreactor runs using a proprietary CHO-DG44 cell line. Control pH (7.0±0.1), dissolved oxygen (40%±5%), and temperature (36.5°C). Use a chemically defined basal and feed media.
- Data Collection Schedule: Sample twice daily for 14 days.
- Cell Metrics: Count total and viable cells (via trypan blue exclusion) for viable cell density (VCD) and viability.
- Metabolite Analysis: Use a bioanalyzer (e.g., Nova Bioprofile) to quantify concentrations of glucose, glutamine, glutamate, lactate, ammonium, and 18 other amino acids.
- Product Titer: Measure IgG titer using Protein A HPLC.
- Offline Gas Analysis: Measure CO2 and O2 in exhaust gas via mass spectrometry.
- Model Calibration: Use data from Reactor Runs 1 & 2. Import time-course data into modeling software (e.g., MATLAB, Python with SciPy). Employ a non-linear least squares algorithm to estimate unknown kinetic parameters (e.g.,
µ_max,K_Glc,Y_Lac/Glc) that minimize the difference between model predictions and experimental data. - Model Validation: Use data from Reactor Run 3, which was not used in calibration. Run the calibrated model with the same initial conditions and feed strategy as Run 3. Quantitatively compare the model's predictions for VCD, key metabolites (lactate, ammonia), and final titer against the actual Run 3 data. Use statistical metrics like Root Mean Square Error (RMSE) and Relative Error.
Diagram Title: Kinetic Model Calibration and Validation Workflow
The Scientist's Toolkit: Key Reagent Solutions for Model Validation Research
Table 2: Essential Research Reagents and Materials for CHO Kinetic Studies
| Item | Function in Research | Example / Specification |
|---|---|---|
| Chemically Defined Media | Provides a consistent, animal-component-free nutrient base. Essential for deriving accurate nutrient consumption/secretion rates. | Gibco CD FortiCHO or comparable in-house formulations. |
| Feed Supplements | Concentrated nutrient solutions added during fed-batch. Critical for modeling fed-batch dynamics and nutrient limitations. | Proprietary feed blends (e.g., Cell Boost). |
| Metabolite & Gas Analyzers | Provides high-frequency, multi-analyte data (metabolites, gases) for model calibration/validation. | Nova Bioprofile FLEX2; MS-based off-gas analyzer (e.g., DASGIP). |
| Cell Counter & Viability Analyzer | Generates essential growth kinetics data (VCD, viability). | Automated system using trypan blue (e.g., Cedex XS). |
| Product Titer Assay Kits | Quantifies monoclonal antibody concentration over time, the key output variable. | Protein A HPLC columns or plate-based assays (e.g., SoloVPE). |
| Process Control Software & Bioreactors | Enables precise, automated control of environmental parameters (pH, DO, Temp) for reproducible data generation. | DASware control software on ambr or bench-top bioreactor systems. |
| Modeling & Optimization Software | Platform for coding, calibrating, simulating, and validating kinetic models. | MATLAB with SimBiology, Python (SciPy, NumPy), or gPROMS. |
Building and Applying CHO Kinetic Models: A Step-by-Step Methodological Guide
Comparison Guide: Model Prediction Accuracy for CHO Cell Growth
This guide compares the predictive performance of three kinetic modeling approaches used in CHO cell culture for monoclonal antibody production. The validation context is the prediction of viable cell density (VCD) and titer over a 14-day fed-batch process.
Table 1: Model Performance Comparison for Key Culture Metrics
| Model Type | Data Sources Integrated | Avg. VCD Prediction Error (%) | Avg. Titer Prediction Error (%) | Required Compute Time per Simulation |
|---|---|---|---|---|
| Traditional Mechanism-Based | Historical runs only | 18.5 | 22.1 | 2 minutes |
| Hybrid (Mechanistic + ML) | Historical runs, Transcriptomics (bulk RNA-seq) | 9.8 | 12.4 | 45 seconds |
| Fully Integrated Data-Driven (Proposed) | Historical runs, Multi-omics (RNA-seq, Metabolomics), Real-Time Sensors (pH, pO2, pCO2, Online VCD) | 4.2 | 5.7 | 15 seconds (plus real-time update) |
Experimental Data Source: Model validation was performed against 12 independent, previously unseen 5L bioreactor runs. Error is reported as the mean absolute percentage error (MAPE) at the end of the production phase (day 14).
Experimental Protocol for Model Validation
Objective: To validate the predictive capability of the fully integrated data-driven model against established alternatives.
Methodology:
- Cell Line & Culture: A CHO-S cell line expressing a recombinant IgG1 antibody was used.
- Bioreactor System: Twelve parallel 5L bench-top bioreactors were operated in fed-batch mode for 14 days. Baseline conditions were identical, but induced perturbations included shifts in temperature (+0.5°C), pH (±0.1), and feed timing to generate variability.
- Data Acquisition:
- Historical Runs: Data from 50 prior historical runs were used for initial model training.
- Omics Data: Daily samples were taken for intracellular metabolomics (LC-MS) and transcriptomics (RNA-seq). Data was normalized and integrated as time-series inputs.
- Real-Time Sensors: pH, dissolved oxygen (pO2), dissolved CO2 (pCO2), and online capacitance (for VCD) data were streamed every minute.
- Model Execution & Prediction: At the end of day 5, each model type was initialized with the available run data up to that point. Each model was tasked with predicting the trajectory of VCD and titer from day 6 to day 14.
- Validation: Model predictions were compared to the actual measured outcomes from the 12 validation runs. The mean absolute percentage error (MAPE) was calculated for the final day values.
Visualizing the Integrated Modeling Workflow
Diagram 1: Data Integration Workflow for CHO Kinetic Model
Diagram 2: Simplified CHO Cell Central Metabolism Pathway
The Scientist's Toolkit: Research Reagent Solutions for Integrated CHO Modeling
Table 2: Essential Materials for Data-Driven CHO Model Experiments
| Item / Reagent | Function in Research Context |
|---|---|
| CHO-S Cell Line (expressing target mAb) | The foundational biological system for model development and validation. |
| Bench-Top Bioreactor System (e.g., Sartorius Ambr 250) | Provides controlled, parallel, and scalable environments for generating historical and validation culture data. |
| Multi-Analyte Bioprocess Sensors (for pH, DO, CO2) | Generate the core real-time data stream for monitoring and model input. |
| Online Biomass Analyzer (e.g., capacitance probe) | Provides real-time estimates of viable cell density, a critical state variable for the model. |
| RNA Extraction & Sequencing Kit (e.g., from Illumina) | Enables transcriptomic profiling to capture cellular metabolic and secretory state. |
| Metabolomics Sample Prep Kit & LC-MS Platform | Allows quantification of intracellular and extracellular metabolites for flux analysis. |
| Process Data Management Software (e.g., Umetrics Suite) | Crucial for aggregating and aligning time-series data from disparate sources (sensors, omics, offline assays). |
| Modeling Software Environment (e.g., Python with SciPy/TensorFlow, or MATLAB) | Platform for building and executing the hybrid mechanistic-machine learning kinetic model. |
Within the context of kinetic model validation for Chinese Hamster Ovary (CHO) cell bioprocesses, three critical parameters are paramount: the maximum specific growth rate (μmax), substrate-to-biomass yield coefficients (Yx/s), and maintenance coefficients (m_s). Accurate determination of these parameters is essential for predictive model development, which drives process optimization and control in therapeutic protein production. This guide compares methodologies for parameter estimation and their impact on model predictions.
Quantitative Parameter Comparison
Table 1 summarizes typical values and estimation methods for key kinetic parameters in CHO cell fed-batch cultures, as reported in recent literature.
Table 1: Comparison of Critical Kinetic Parameters and Estimation Methods
| Parameter | Typical Range (CHO Fed-Batch) | Common Estimation Method | Key Influencing Factors | Impact on Model Prediction |
|---|---|---|---|---|
| μ_max (h⁻¹) | 0.03 – 0.06 | Exponential growth phase fitting, Logistic/Monod model fit | Temperature, pH, glutamine level, clone-specific metabolism | Directly sets maximum biomass accumulation rate; overestimation leads to premature nutrient depletion forecasts. |
| Y_x/s (gDCW/g) | For Glucose: 0.3 – 0.6For Glutamine: 0.4 – 0.9 | Linear regression of ΔX vs. ΔS (consumed) during growth phase | Metabolic shift (e.g., lactate production), byproduct formation. | Underestimates nutrient demand if yield is overestimated, affecting feed strategy design. |
| m_s (g/gDCW/h) | For Glucose: 1e-3 – 6e-3For Glutamine: 5e-4 – 2e-3 | Linear regression of q_s vs. μ (Herbert-Pirt relation) | Cellular stress, osmolality, energy demand for product synthesis. | Neglect leads to under-prediction of base substrate needs at low growth rates (e.g., stationary/production phase). |
Experimental Protocols for Parameter Determination
Protocol 1: Estimation of μmax and Yx/s via Batch Culture
Objective: Determine maximum specific growth rate and yield coefficient from substrate consumption.
- Inoculation: Seed CHO cells in a controlled bioreactor with known initial concentrations of biomass (X₀) and primary substrates (S₀, e.g., glucose, glutamine).
- Monitoring: Sample at frequent intervals (e.g., every 12 hours) to measure:
- Viable Cell Density (VCD): Via trypan blue exclusion.
- Substrate Concentrations: Via HPLC or bioanalyzer.
- Data Analysis:
- μmax: Fit the exponential phase of the ln(VCD) vs. time plot. The slope is μ. The maximum observed μ is μmax.
- Yx/s: Plot cumulative biomass produced (X - X₀) against cumulative substrate consumed (S₀ - S). The slope of the linear region is Yx/s.
Protocol 2: Estimation of Maintenance Coefficient (m_s) via Chemostat or Fed-Batch Data
Objective: Decouple growth-associated and non-growth-associated substrate consumption.
- Experimental Setup: Perform a series of steady-state chemostat runs at different dilution rates (D) or analyze data from a fed-batch where μ declines over time.
- Measurement: At each steady state (or time point), determine the specific substrate consumption rate (qs = (Sin - S_out)*D / X for chemostat).
- Data Analysis: Apply the Herbert-Pirt relationship: qs = (1/Yx/s)^max * μ + ms. Plot qs against μ. The y-intercept provides the maintenance coefficient ms, and the slope provides the reciprocal of the true maximum yield (1/Yx/s)^max.
Logical Flow of Parameter Estimation in Model Validation
Diagram Title: Workflow for Kinetic Parameter Estimation and Model Validation
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Kinetic Parameter Studies
| Item | Function in Parameter Estimation | Example/Notes |
|---|---|---|
| Chemically Defined (CD) Medium | Provides reproducible basal nutrient levels for accurate substrate tracking. | Gibco CD CHO, EX-CELL Advanced. |
| Metabolite Assay Kits / Bioanalyzer | Quantify glucose, glutamine, lactate, ammonia concentrations for yield & maintenance calc. | Nova Bioprofile analyzers, YSI Biochemistry Analyzer. |
| Cell Counter with Viability | Accurately measure viable cell density (VCD) for growth rate (μ) calculation. | Beckman Coulter Vi-Cell BLU, automated trypan blue. |
| Substrate-Limited Feed Solutions | Enable precise control of nutrient delivery in fed-batch for qs and ms studies. | Custom feeds with defined glucose/amino acid levels. |
| Process Control Software & Bioreactors | Maintain consistent environmental conditions (pH, DO, temp) for reproducible kinetics. | DASware, BioFlo systems. |
| Modeling & Statistical Software | Perform linear/non-linear regression for parameter fitting and sensitivity analysis. | MATLAB, Python (SciPy), Prism. |
The comparative analysis underscores that no single method universally excels for estimating μmax, Yx/s, and m_s. The choice depends on process modality (batch vs. fed-batch) and data quality. Robust model validation requires independent datasets, and parameters should be treated as interconnected rather than isolated constants. Accurate determination of these core parameters forms the foundation of predictive models that can accelerate and de-risk biopharmaceutical process development.
This guide provides a comparative analysis of three parameter estimation techniques—Nonlinear Regression (NLR), Maximum Likelihood Estimation (MLE), and Bayesian Inference—within the context of validating kinetic models for Chinese Hamster Ovary (CHO) cells. Accurate parameter estimation is critical for predicting cell growth, metabolite consumption, and recombinant protein production in biopharmaceutical development.
Comparative Performance Analysis
The following table summarizes the performance of each technique based on synthetic and experimental data from CHO cell kinetic studies (e.g., modeling glucose consumption, lactate production, and monoclonal antibody expression).
Table 1: Comparison of Parameter Estimation Techniques for CHO Cell Kinetic Models
| Criterion | Nonlinear Regression (NLR) | Maximum Likelihood (MLE) | Bayesian Inference |
|---|---|---|---|
| Primary Objective | Minimize sum of squared errors. | Maximize likelihood function. | Obtain posterior distribution. |
| Uncertainty Quantification | Confidence intervals (frequentist). | Confidence intervals from Fisher information. | Full posterior credible intervals. |
| Prior Information | Not incorporated. | Not incorporated. | Explicitly incorporated via prior distributions. |
| Computational Cost | Low to moderate. | Moderate. | High (MCMC sampling). |
| Robustness to Noise | Moderate; sensitive to outliers. | Good with correct error model. | Good; priors can regularize. |
| Identifiability Analysis | Local approximations (Hessian). | Local approximations. | Global (full posterior). |
| Implementation Complexity | Low (e.g., Levenberg-Marquardt). | Moderate (requires likelihood). | High (requires MCMC/tuning). |
| Best For | Simple models, quick estimates. | Well-characterized error structures. | Complex models, scarce data, leveraging prior knowledge. |
Table 2: Example Results from a CHO Cell Growth Model Fit (Pseudo-Data) Model: µ = µ_max * (S/(K_s + S)) where µ is growth rate, S is substrate concentration.
| Technique | Estimated µ_max (h⁻¹) | Estimated K_s (mM) | Time to Converge (s) | AIC Score |
|---|---|---|---|---|
| NLR (LSQ) | 0.045 ± 0.002 | 0.15 ± 0.03 | 1.2 | -125.3 |
| MLE (Normal Err) | 0.046 ± 0.002 | 0.14 ± 0.02 | 2.5 | -128.7 |
| Bayesian (MCMC) | 0.047 [0.043, 0.050] | 0.13 [0.10, 0.17] | 185.7 | -127.1 |
Experimental Protocols for Cited Studies
Protocol 1: Generating Calibration Data for CHO Kinetic Models
- Cell Culture: Seed CHO-S cells in a fed-batch bioreactor with proprietary medium.
- Monitoring: Sample every 12 hours for 10 days. Measure viable cell density (VCD) via trypan blue exclusion, and metabolite concentrations (glucose, lactate, glutamine) via bioanalyzer.
- Product Titer: Measure monoclonal antibody concentration using Protein A HPLC.
- Data Curation: Assemble time-series dataset of VCD, metabolites, and titer. Normalize data to initial conditions.
Protocol 2: Parameter Estimation Workflow
- Model Definition: Use a structured kinetic model (e.g., dynamical system with 5-10 ODEs for cell growth, metabolism, and production).
- Error Model Specification: For MLE, assume independent, normally distributed measurement errors with variance proportional to magnitude.
- Optimization/Sampling:
- NLR: Implement in Python (
scipy.optimize.curve_fit) or MATLAB (nlinfit). - MLE: Use MATLAB's
mleor Python'sstatsmodelswith custom likelihood. - Bayesian: Implement in Stan or PyMC3 with weakly informative priors (e.g., Half-Normal for positive parameters). Run 4 MCMC chains, 5000 iterations each.
- NLR: Implement in Python (
- Diagnostics: Assess convergence (Gelman-Rubin statistic for Bayesian), residual plots (NLR, MLE), and posterior predictive checks (Bayesian).
Visualizations
Title: Parameter Estimation Technique Selection Workflow
Title: Simplified CHO Cell Metabolic Pathway for Modeling
The Scientist's Toolkit: Key Research Reagent Solutions
Table 3: Essential Materials for CHO Cell Kinetic Modeling Experiments
| Item | Function & Explanation |
|---|---|
| CHO-S Cells | Host cell line for recombinant protein production; provides the biological system for kinetic study. |
| Chemically Defined Medium | Ensures reproducible growth conditions and precise nutrient tracking for model inputs. |
| Bioanalyzer / Nova Analyzer | Quantifies key metabolites (glucose, lactate, ammonia) in culture supernatant at high frequency. |
| Trypan Blue Stain | Enables viable cell counting via manual hemocytometer or automated cell counter. |
| Protein A HPLC Columns | Gold-standard for accurate quantification of antibody titer over time. |
| MATLAB with Optimization Toolbox | Software platform for implementing NLR and MLE algorithms on ODE models. |
| Stan/PyMC3 Library | Probabilistic programming languages for implementing Bayesian inference with MCMC sampling. |
| Bioreactor Control System | Maintains precise environmental control (pH, DO, temperature) for consistent process data. |
Thesis Context
This comparison guide is framed within ongoing research for the validation of Chinese Hamster Ovary (CHO) cell kinetic models. The objective is to evaluate the predictive power and utility of different in silico platforms for optimizing fed-batch processes, a critical step in biopharmaceutical development.
Platform Performance Comparison
Table 1: Comparison of In Silico Platform Performance for CHO Cell Fed-Batch Optimization
| Platform / Model Type | Core Methodology | Predicted vs. Experimental VCD (Peak, % Error) | Predicted vs. Experimental Titer (Final, % Error) | Key Strength for Media/Feed Design | Reference Study Year |
|---|---|---|---|---|---|
| Mechanistic Kinetic Model (e.g., Cybernetic) | Systems of ODEs describing metabolism & regulation. | 96.2% match (±3.8%) | 94.5% match (±5.5%) | Identifies optimal glutamine/glucose feed ratio to reduce ammonia. | 2022 |
| Hybrid Semi-Parametric Model | Combines mechanistic growth with ML for metabolite dynamics. | 98.1% match (±1.9%) | 97.8% match (±2.2%) | Robust prediction of growth under varying feed spike times. | 2023 |
| Pure ML (ANN) Model | Artificial Neural Networks trained on historical data. | 92.7% match (±7.3%) | 90.1% match (±9.9%) | Rapid screening of 1000s of feed component combinations. | 2023 |
| Flux Balance Analysis (FBA) Model | Genome-scale metabolic network constrained by uptake rates. | 88.5% match (±11.5%) | 86.3% match (±13.7%) | Pinpoints media deficiencies (e.g., serine) for base formulation. | 2021 |
Experimental Protocol for Model Validation
The following protocol was central to generating the comparative data in Table 1.
Title: Fed-Batch Cultivation for CHO Model Calibration and Validation Cell Line: CHO-S producing a monoclonal IgG. Basal Media: Commercially available, chemically defined media.
- Inoculation: Bioreactors seeded at 0.3 x 10^6 cells/mL in 2L working volume.
- Control Cultivation: Standard fed-batch with bolus glucose/amino acid feed on days 3, 5, 7.
- Model-Guided Cultivation: Feed strategy (timing and composition) dictated by the in silico model's prediction for maximizing integral of viable cell density (IVCD) and titer.
- Monitoring: Daily samples for viable cell density (VCD), viability, metabolites (glucose, lactate, ammonia, amino acids), and titer (Protein A HPLC).
- Data Splitting: Data from 5 bioreactors used for model calibration/training. Data from 3 independent bioreactors used for model validation.
- Comparison Metric: The percent match is calculated as:
[1 - |(Predicted - Experimental)/Experimental|] * 100.
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Materials for CHO Kinetic Model Validation
| Item | Function in Experiment |
|---|---|
| Chemically Defined Basal & Feed Media | Provides consistent, animal-component-free nutrient base; variable component for optimization studies. |
| Metabolite Analyzer (e.g., Bioprofile FLEX2) | Measures key extracellular metabolites (glucose, lactate, ammonia) for model calibration. |
| Automated Cell Counter (e.g., Vi-CELL BLU) | Provides accurate VCD and viability, the primary growth kinetic inputs for models. |
| Amino Acid Analysis Kit (HPLC/MS) | Quantifies all 20 amino acids to constrain metabolic models (FBA) and identify limitations. |
| Process Control Software (e.g., DASware) | Logs real-time process data (pH, DO, temp) and enables precise implementation of model-derived feeding schedules. |
| Modeling Software Suite (e.g., MATLAB, Python SciPy, Copasi) | Platform for building, simulating, and calibrating mechanistic or hybrid kinetic models. |
Visualizations
Title: In Silico Model Development and Validation Workflow
Title: Key CHO Cell Metabolic Pathways for Kinetic Modeling
This comparison guide, framed within a broader thesis on Chinese Hamster Ovary (CHO) cell kinetic model validation research, objectively evaluates model performance for bioprocess prediction. The focus is on comparing traditional mechanistic models, hybrid machine learning (ML) models, and modern platform-based digital twins.
Experimental Data Comparison: Model Prediction Performance
The following table summarizes experimental validation data from recent studies, comparing the predictive accuracy of different modeling approaches for key scale-up parameters in CHO cell cultures.
Table 1: Model Performance Comparison for CHO Cell Process Prediction
| Model Type | Example Platform/Tool | Prediction Target (RMSE / Error) | Key Experimental Outcome | Reference Year |
|---|---|---|---|---|
| Traditional Mechanistic | Dynamic Flux Balance Analysis (dFBA) | Viable Cell Density (VCD): ~12% errorTiter: ~18% error | Captures metabolic shifts but requires extensive a priori knowledge; struggles with novel processes. | 2022 |
| Hybrid ML-Mechanistic | Hybrid (LSTM + Monod Kinetics) | Titer: 8.5% RMSECritical Aggregation (CQA): <5% error | Superior prediction of non-linear titer trajectories and CQAs by coupling first principles with data. | 2023 |
| Platform Digital Twin | Siemens Process Insights / Umetrics | Scale-Up Titer: 94% accuracyLactate Shift (CQA): >90% accuracy | Integrated multivariate (PAT) data enables real-time prediction of scale-up failure modes. | 2024 |
| Explainable AI (XAI) | SHAP-integrated Random Forest | IgG Glycosylation (CQA): >87% accuracy | Identifies key media components (e.g., Mn2+, UDP-sugars) driving glycosylation heterogeneity. | 2023 |
Detailed Experimental Protocols
Protocol 1: Hybrid Model Validation for Titer and Aggregation Prediction
- Cell Culture: N-1 bioreactors inoculated with CHO-S cells producing a monoclonal antibody (mAb). The process transitions from growth to production phase via temperature shift.
- Data Acquisition: Offline: Daily samples for VCD, viability, metabolites (glucose, lactate, ammonia), titer (Protein A HPLC), and soluble aggregate (Size-Exclusion Chromatography). Online: Dissolved oxygen (DO), pH, capacitance.
- Model Training: A Long Short-Term Memory (LSTM) network is trained on the first 7 days of process data from 3L bioreactors (n=12). The output is fed into a modified Monod kinetics layer representing nutrient-limited antibody production.
- Validation: The trained hybrid model predicts the final 7-day titer and aggregate levels in 3L validation batches (n=5) and a scaled-up 2000L run. Predictions are compared to actual analytics.
Protocol 2: Digital Twin for Scale-Up Failure Mode Prediction
- Platform Setup: A digital twin is configured in Siemens Process Insights using historical data from 50L, 500L, and 2000L runs of the same mAb process.
- Multivariate Analysis: A Partial Least Squares (PLS) model is built correlating 22 process parameters (e.g., pCO2, osmolality, feeding rates) with CQAs (charge variants, glycan profiles).
- Real-Time Simulation: Live data from a new 500L scale run is fed into the digital twin. The model performs a similarity analysis against the historical design space.
- Outcome Prediction: The system flags deviations (e.g., elevated lactate) and predicts their impact on the final titer and product quality if scaled to 2000L without intervention.
Visualization of Modeling Workflows
Diagram 1: Hybrid ML-Mechanistic Model Workflow for CHO Cells
Diagram 2: Digital Twin-Enabled Scale-Up Prediction Logic
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Model Validation Studies
| Research Reagent / Solution | Function in Model Validation |
|---|---|
| Chemically Defined (CD) Media Platform (e.g., Gibco Dynamis, Sartorius Cellvento) | Provides a consistent, animal-component-free basal and feed media foundation, reducing noise for robust model training. |
| Metabolite Analysis Kits (e.g., Nova Bioprofile Flex, Cedex Bio HT) | Enables high-frequency, accurate measurement of glucose, lactate, glutamine, and ammonia for kinetic parameter estimation. |
| PAT Probes (e.g., Raman Spectrometer, Dielectric Spectroscopy) | Delivers real-time, multivariate data (cell density, metabolites, product titer) for digital twin calibration and feedback. |
| CQA Analytics Suite (e.g., HPLC-SEC, HILIC, icIEF) | Quantifies critical quality attributes (aggregates, glycan species, charge variants) as essential model output validation targets. |
| Modeling Software (e.g., MATLAB SimBiology, Python SciKit, Umetrics) | Provides the computational environment for building, simulating, and validating kinetic, statistical, and hybrid models. |
Overcoming Common Pitfalls: Troubleshooting and Refining CHO Cell Kinetic Models
Diagnosing and Solving Model Identifiability and Parameter Correlation Issues
Within the context of Chinese Hamster Ovary (CHO) cell kinetic model validation research, ensuring model identifiability and managing parameter correlation are critical for generating reliable, predictive models of cell growth, metabolism, and recombinant protein production. Non-identifiable models and highly correlated parameters undermine confidence in model predictions and their utility in bioprocess optimization. This guide compares methodologies for diagnosing and resolving these issues, supported by experimental data from recent studies.
Comparison of Diagnostic Approaches
The table below summarizes the performance of key diagnostic techniques used in CHO cell kinetic modeling.
Table 1: Comparison of Identifiability & Correlation Diagnostic Methods
| Diagnostic Method | Primary Output | Computational Cost | Sensitivity to Noise | Key Insight Provided | Typical Application in CHO Models |
|---|---|---|---|---|---|
| Fisher Information Matrix (FIM) Analysis | Parameter confidence intervals, correlation matrix | Low to Moderate | Moderate | Identifies unidentifiable parameters and pairwise correlations | Monod/growth kinetic parameter estimation from fed-batch data |
| Profile Likelihood Analysis | Likelihood profiles for each parameter | High | Low | Uniquely detects structural non-identifiability and practical identifiability limits | Validation of apoptosis or metabolic pathway model parameters |
| Monte Carlo Sampling (e.g., MCMC) | Posterior parameter distributions | Very High | Low | Reveals full correlation structure and practical identifiability in high dimensions | Complex mechanistic models of glycosylation or central carbon metabolism |
| Singular Value Decomposition (SVD) of FIM | Eigenvalues/Eigenvectors, parameter subset selection | Low | High | Identifies sloppy directions (parameter combinations poorly constrained by data) | Simplification of large signal transduction pathway models |
| Local Sensitivity Analysis (Normalized) | Sensitivity coefficients (e.g., ∂y/∂θ × θ/y) | Very Low | High | Highlights parameters with negligible influence on model outputs; prerequisite for FIM | Screening before detailed identifiability analysis of nutrient uptake models |
Experimental Protocols for Key Cited Studies
Protocol 1: Profile Likelihood for a CHO Cell Growth and Lactate Metabolism Model
- Model Formulation: Develop an ordinary differential equation (ODE) model encompassing cell density, glucose, glutamate, and lactate dynamics.
- Data Collection: Perform parallel fed-batch bioreactor runs (n=3) with daily sampling for viable cell density (trypan blue exclusion), metabolite concentrations (HPLC), and product titer.
- Parameter Estimation: Use maximum likelihood estimation to fit the model to the experimental data, obtaining nominal parameter values.
- Profiling: For each parameter θᵢ, fix it at a range of values around its nominal estimate. Re-optimize all other parameters at each fixed value to minimize the sum of squared errors.
- Diagnosis: Plot the optimized objective function value against the fixed parameter value. A flat profile indicates structural non-identifiability. A profile with a minimum but wide, shallow valleys suggests poor practical identifiability.
Protocol 2: Monte Carlo Markov Chain (MCMC) for a N-Glycosylation Pathway Model
- Prior Definition: Assign physiologically plausible prior distributions (e.g., log-uniform) to all kinetic parameters (e.g., enzyme Vmax, Km) in the glycosylation network model.
- Likelihood Definition: Construct a likelihood function based on measured glycoform distribution data (from capillary electrophoresis or LC-MS) at multiple time points.
- Sampling: Employ a Metropolis-Hastings or Hamiltonian Monte Carlo algorithm to draw samples from the posterior parameter distribution. Run multiple chains (>100,000 iterations each).
- Convergence & Analysis: Assess chain convergence using the Gelman-Rubin statistic. Analyze the posterior distributions: narrow, single-peaked distributions indicate identifiable parameters; broad or multi-modal distributions indicate non-identifiability. Analyze the posterior correlation matrix for strong (>0.9) correlations.
Visualizations
Diagram 1: Workflow for Diagnosing Identifiability in CHO Models
Diagram 2: Key Pathways in CHO Cell Kinetic Models Prone to Correlation
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Reagents for CHO Model Validation Experiments
| Reagent / Material | Function in Identifiability Studies | Example Vendor/Product |
|---|---|---|
| Chemically Defined Fed-Batch Medium | Provides consistent, traceable nutrient levels for generating high-quality kinetic data, reducing experimental noise that confounds identifiability analysis. | Gibco CD FortiCHO, Sartorius Cellvento 4CHO |
| Bioanalyzer / Automated Cell Counter | Accurately measures viable cell density and viability (e.g., via trypan blue), a critical state variable for all growth-associated kinetic models. | Bio-Rad TC20, Nexcelom Cellometer |
| Metabolite Analysis Kit (Glucose, Lactate, Glutamine) | Enables frequent, precise measurement of key extracellular metabolite concentrations for constructing mass balance-based kinetic models. | Roche Cedex Bio HT, YSI 2950 Biochemistry Analyzer |
| LC-MS/MS System | Quantifies intracellular metabolites, amino acids, or glycoform distributions for complex metabolic pathway models where parameter correlation is common. | Thermo Scientific Orbitrap, Agilent 6495C QQQ |
| Process Data Management Software | Securely logs and time-aligns all bioreactor process data (pH, DO, feeding rates) with analytical samples, ensuring a consistent dataset for estimation. | Sartorius ambr crossflow, DASware |
| Parameter Estimation & Modeling Software | Provides algorithms (MLE, MCMC, profile likelihood) specifically designed for diagnosing identifiability and correlation in nonlinear biological models. | MATLAB with SimBiology, R with dMod or FME, COPASI |
This guide compares methodologies for kinetic model parameter estimation in Chinese Hamster Ovary (CHO) cell cultures, focusing on performance under data scarcity and measurement noise. Reliable parameter estimation is critical for validating metabolic and growth models used in bioprocess optimization.
Comparison of Parameter Estimation Methodologies
The following table summarizes the performance of four prominent estimation strategies when applied to a typical CHO cell kinetic model (focused on growth, glucose consumption, and lactate production) under constrained and noisy data conditions.
Table 1: Performance Comparison of Parameter Estimation Strategies
| Method / Strategy | Avg. Parameter Error (Low Noise) | Avg. Parameter Error (High Noise) | Min. Data Points Required | Computational Cost | Robustness to Initial Guesses |
|---|---|---|---|---|---|
| Ordinary Least Squares (OLS) | 12.5% | 47.8% | 15 per variable | Low | Poor |
| Bayesian Inference (MCMC) | 8.2% | 22.1% | 10 per variable | Very High | Excellent |
| Regularized Regression (Lasso) | 15.7% | 29.4% | 12 per variable | Medium | Good |
| Profile Likelihood Analysis | 9.1% | 31.5% | 20 per variable | High | Good |
Experimental Context: Error percentages represent the average deviation from parameters calibrated on a complete, low-noise dataset. The model includes 8 key kinetic parameters. High noise conditions simulate a 15% coefficient of variation in measurements.
Detailed Experimental Protocols
Protocol 1: Benchmarking Estimation Methods with Synthetic Data
- Model Simulation: A established CHO cell structured kinetic model (e.g., for cell growth, substrate, and metabolites) is used to generate a high-resolution "ground truth" dataset.
- Data Subsampling & Noise Injection: The full dataset is sub-sampled to create scarce datasets (e.g., 5-20 time points). Gaussian noise is added at two levels: "Low" (5% CV) and "High" (15% CV).
- Parameter Estimation: Each method (OLS, Bayesian MCMC, etc.) is applied to the perturbed datasets to estimate the model's kinetic parameters.
- Validation: Estimated parameters are used to simulate cell culture profiles, which are compared against the held-out "ground truth" data using the normalized root mean square error (NRMSE).
Protocol 2: Experimental Validation with Fed-Batch Culture
- CHO Cell Culture: A CHO-K1 cell line producing a model monoclonal antibody is cultivated in a controlled fed-batch bioreactor.
- Sparse Sampling: Samples are taken at strategically spaced intervals (every 12 hours) to mimic data scarcity, measuring viable cell density (VCD), glucose, glutamate, lactate, ammonium, and titer.
- Model Calibration: The sparse, noisy experimental data is used with Bayesian Inference to estimate parameters for a combined growth and product formation model.
- Prediction Check: The calibrated model predicts the final 48 hours of the culture profile, which is then compared against a more frequently sampled validation dataset.
Visualization of Key Concepts
Diagram 1: Robust Parameter Estimation Workflow
Diagram 2: Simplified CHO Cell Metabolic Pathways for Kinetic Modeling
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Kinetic Model Validation Studies
| Item / Reagent | Function in Context | Key Consideration |
|---|---|---|
| Chemically Defined (CD) Media | Provides a consistent, fully known substrate environment for model calibration and validation. | Eliminates unknown variables from serum for precise kinetic analysis. |
| Bioanalyzer / Cell Counter | Provides accurate, frequent measurements of viable cell density (VCD) and viability, a primary state variable. | Essential for generating the growth kinetics data. Automated systems enable high-frequency sampling. |
| Metabolite Analyzer (HPLC/Bioanalyzer) | Quantifies key extracellular metabolites (glucose, lactate, glutamate, ammonium) for mass balance and kinetic rate calculations. | Measurement speed and precision directly impact parameter estimation error. |
| LC-MS for Intracellular Metabolites | Enables flux analysis by measuring intermediate metabolite pools, strengthening model identifiability. | Required for more advanced, structured kinetic models. |
| Titer Measurement Assay | Quantifies monoclonal antibody product concentration over time to model production kinetics. | Platform (e.g., Protein A HPLC, Octet) must be compatible with matrix effects from spent media. |
| Process Control Software & Bioreactor | Allows for precisely controlled fed-batch or perfusion experiments to test model predictions under dynamic conditions. | Critical for the final step of experimental model validation. |
Within the critical field of biopharmaceutical development, the construction and validation of kinetic models for Chinese Hamster Ovary (CHO) cells presents a fundamental challenge: optimizing model complexity. An overly simplistic model (underfitting) fails to capture essential cellular dynamics, while an overly complex model (overfitting) memorizes noise in the training data, leading to poor generalizability. This guide compares methodologies and tools essential for achieving this balance, directly impacting the reliability of predictions for cell growth, metabolite consumption, and recombinant protein production.
Comparison of Model Validation Techniques
The following table summarizes quantitative performance metrics for three common modeling approaches when applied to a standardized CHO cell batch culture dataset (Glucose, Glutamine, Lactate, Ammonia, Viable Cell Density, Titer). The dataset was split 70/30 for training and testing.
Table 1: Performance Comparison of Modeling Techniques on CHO Cell Kinetics
| Modeling Technique | Training R² | Test R² | Mean Absolute Error (Test) | Key Risk |
|---|---|---|---|---|
| Monod-based ODE (Low Complexity) | 0.72 | 0.70 | 12.5 | Underfitting: Fails to capture transition to stationary phase. |
| Mechanistic Dynamic Flux Balance (Medium Complexity) | 0.88 | 0.85 | 6.8 | Balanced: Robust prediction of metabolic shifts. |
| Deep Neural Network - 5 Hidden Layers (High Complexity) | 0.99 | 0.75 | 10.2 | Overfitting: Excellent training, poor unseen data performance. |
| Regularized DNN (L2) + Dropout | 0.92 | 0.89 | 5.1 | Optimal: Mitigated overfitting, best generalizability. |
Detailed Experimental Protocols
Protocol 1: Cross-Validation for Mechanistic Model Selection
- Data Preparation: Collect time-series data from 15 independent CHO fed-batch runs. Normalize all measurements (metabolites, cell density) using Z-score.
- Model Candidates: Develop three ODE-based kinetic models with increasing numbers of state variables (5, 9, 14).
- k-Fold Validation: Split the 15-run dataset into 5 folds (3 runs each). For each model, iteratively train on 4 folds and validate on the held-out fold.
- Evaluation Metric: Calculate the average Root Mean Square Error (RMSE) across all 5 folds for the prediction of final titer and integral of viable cell density (IVCD).
- Selection: Choose the model with the lowest average cross-validation RMSE that shows no significant improvement with added complexity.
Protocol 2: Regularization Test for Neural Network Models
- Network Architecture: Construct a feedforward neural network with input layer (6 nodes), three hidden layers (32 nodes each), and output layer (titer prediction).
- Baseline Training: Train the network for 500 epochs on the training set without regularization, monitoring loss.
- Regularized Training: Repeat training with:
- L2 Regularization: Add a penalty term (λ=0.01) to the loss function based on the sum of squared weights.
- Dropout: Randomly disable 20% of neurons in each hidden layer during each training iteration.
- Early Stopping: Monitor validation set error; halt training when no improvement is seen for 50 consecutive epochs.
- Comparison: Compare the Test R² and error metrics of the baseline and regularized models (Table 1).
Visualizing the Model Validation Workflow
Title: Workflow for Balancing Model Complexity in CHO Cell Modeling
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Cell Kinetic Modeling Experiments
| Item | Function in Context | Example Product/Kit |
|---|---|---|
| CHO Serum-Free Media | Provides consistent, defined base for cell culture to reduce experimental noise. | Gibco CD CHO AGT Medium |
| Bioanalyzer / Cell Counter | Accurately quantifies viable cell density (VCD) and viability, a primary model input. | Bio-Rad TC20 / Beckman Coulter Vi-CELL BLU |
| Metabolite Analyzer | Measures key metabolite concentrations (Glucose, Lactate, Ammonia) for kinetic fitting. | YSI 2950 Biochemistry Analyzer / Cedex Bio HT |
| Recombinant Protein Titer Assay | Quantifies product output (e.g., IgG), the critical quality output for model prediction. | HPLC Protein A Assay / Octet BLI-based systems |
| Process Data Management Software | Secures time-series data integrity and enables traceability for model building. | SOLUTION Process Data Management |
| Scientific Computing Environment | Platform for implementing and testing mathematical models and machine learning algorithms. | MATLAB SimBiology / Python (SciPy, TensorFlow/PyTorch) |
Handling Metabolic Shifts and Cell Line-Specific Variations in Long-Term Cultures
Within the context of Chinese Hamster Ovary (CHO) cell kinetic model validation research, managing the inherent metabolic shifts and phenotypic drift in long-term cultures is paramount for bioprocess consistency. This comparison guide evaluates the performance of different culture media supplementation strategies to stabilize metabolic output.
Experimental Comparison of Media Supplements for Metabolic Stabilization
Experimental Protocol: Three CHO-K1 cell lines (clone A: high producer, clone B: growth-optimized, clone C: parental) were cultured in fed-batch mode over 60 days (approximately 90 generations). Basal media was supplemented with one of three strategies: 1) Standard Glucose/Gln Feed, 2) a Commercially Available Balanced Nutrient Feed (BNF), or 3) a custom-designed Adaptive Feed (AF) formulated based on in-line metabolite sensor data (NOVA Bioprofile). Cultures were sampled every 48 hours for extracellular metabolite analysis (HPLC), cell count and viability (trypan blue), and product titer (ELISA). Specific productivity (qP) was calculated. Data from day 30-60 (steady-state period) is summarized below.
Table 1: Metabolic and Productive Performance in Long-Term Culture (Day 30-60 Average)
| Supplement Strategy | Lactate Peak (mM) | Ammonia Peak (mM) | Avg. Viability (%) | qP (pg/cell/day) | Titer Variability (%CV) |
|---|---|---|---|---|---|
| Standard Glucose/Gln Feed | 25.4 ± 3.2 | 6.8 ± 1.1 | 88.2 ± 5.6 | 2.1 ± 0.8 | 22.5 |
| Commercial Balanced Feed (BNF) | 18.1 ± 2.5 | 4.2 ± 0.7 | 91.5 ± 3.2 | 3.5 ± 0.5 | 15.8 |
| Adaptive Feed (AF) | 12.3 ± 1.8 | 2.9 ± 0.5 | 93.8 ± 2.1 | 3.8 ± 0.4 | 9.3 |
Table 2: Cell Line-Specific Response to Adaptive Feed (AF) at Day 60
| CHO Cell Line | Lactate Yield (mol/mol Glu) | Shift to Net Lactate Consumption (Day) | Final Titer (g/L) | Metabolic Shift Magnitude (PCA Score)* |
|---|---|---|---|---|
| Clone A (Producer) | 0.52 ± 0.05 | 42 | 4.2 ± 0.3 | 1.8 |
| Clone B (Growth) | 0.61 ± 0.06 | 55 | 3.1 ± 0.4 | 2.5 |
| Clone C (Parental) | 0.58 ± 0.07 | Not Reached | 1.5 ± 0.2 | 3.1 |
*Higher score indicates greater metabolic drift from baseline.
Protocol for Metabolic Flux Analysis: At days 30 and 60, cells were harvested for intracellular metabolomics. 5x10^6 cells were quenched in cold methanol, extracted, and analyzed via LC-MS. Central carbon metabolism fluxes were estimated using a constrained genome-scale metabolic model (CHO genome). The shift in ATP yield from oxidative phosphorylation vs. glycolysis was used as a key metric of metabolic drift.
The Scientist's Toolkit: Research Reagent Solutions
| Item | Function in Experiment |
|---|---|
| NOVA Bioproflex Analyzer | Provides real-time, in-line monitoring of key metabolites (Glucose, Lactate, Gln, Glu, NH4+). |
| Balanced Nutrient Feed (BNF) | A commercial, chemically defined feed designed to maintain nutrient stoichiometry and reduce waste accumulation. |
| LC-MS/MS System | For targeted quantitation of intracellular metabolites (e.g., TCA cycle intermediates, nucleotides). |
| Metabolic Flux Analysis Software (e.g., INCA) | Uses isotopomer tracing data with a CHO metabolic network model to quantify pathway activity. |
| Clone-Specific Metabolic Models | Genome-scale models (e.g., CHO 1,100+ reactions) tailored to individual producer clones for feed design. |
Feed Strategy Impact on Metabolic Drift
Long-Term Culture Monitoring & Model Update Workflow
Within the context of Chinese Hamster Ovary (CHO) cell kinetic model validation research, iterative model refinement is a critical methodology for enhancing bioprocess predictability and efficiency in drug development. This guide compares the performance of an iterative, data-integrated kinetic modeling approach against traditional static models, using experimental data from fed-batch CHO cell cultures producing monoclonal antibodies (mAbs).
Performance Comparison: Iterative vs. Static Kinetic Models
The table below summarizes a key performance comparison following the integration of new experimental data from a recent metabolic flux analysis (MFA) study. The iterative model (CHO-Dyno v2.1) was benchmarked against a widely cited static metabolic model (iCHO2048) and a traditional Monod-based growth model.
Table 1: Model Performance Comparison for Predicting CHO Cell Behavior in Fed-Batch Culture
| Performance Metric | Iterative Model (CHO-Dyno v2.1) | Static Metabolic Model (iCHO2048) | Traditional Monod-Based Model |
|---|---|---|---|
| Viable Cell Density (VCD) Prediction Error (RMSE) | ±0.45 x 10⁶ cells/mL | ±1.82 x 10⁶ cells/mL | ±2.31 x 10⁶ cells/mL |
| Titer Prediction Error (RMSE) | ±0.12 g/L | ±0.38 g/L | ±0.51 g/L |
| Specific Productivity (qP) Prediction Correlation (R²) | 0.94 | 0.76 | 0.58 |
| Lactate Metabolic Shift Prediction Accuracy | 92% | 65% | 30% |
| Glutamine Depletion Timepoint Error | ±1.8 hours | ±6.5 hours | ±12.4 hours |
| Model Update Cycle Time Post-New Data | 48-72 hours | N/A (Static) | 1-2 weeks |
RMSE: Root Mean Square Error. Data synthesized from recent publications (2023-2024) on CHO systems biology.
Experimental Protocols for Data Generation
The superior performance of the iterative model is contingent on the quality of new experimental data fed into its refinement cycle. Below are the detailed protocols for two key experiments that generate cornerstone datasets.
Protocol 1: Metabolic Flux Analysis (MFA) via ¹³C-Labeled Tracers
Objective: Quantify intracellular metabolic reaction rates to refine the stoichiometric matrix of the kinetic model.
- Culture & Labeling: Grow CHO-DG44 cells in a controlled bioreactor. At mid-exponential phase (Day 3), rapidly replace 80% of the glucose in the feed with [U-¹³C₆]glucose.
- Sampling: Take triplicate samples at 0, 15, 30, 60, 120, and 240 minutes post-pulse. Immediately quench metabolism in 60% (v/v) aqueous methanol at -40°C.
- Metabolite Extraction: Perform a dual extraction using cold methanol, water, and chloroform. Centrifuge and collect the polar (aqueous) phase for intracellular metabolite analysis.
- LC-MS Analysis: Analyze extracts using Hydrophilic Interaction Liquid Chromatography (HILIC) coupled to a high-resolution mass spectrometer.
- Flux Calculation: Use software (e.g., INCA, Isotopomer Network Compartmental Analysis) to fit the measured mass isotopomer distributions (MIDs) and compute net fluxes through central carbon metabolism pathways (glycolysis, TCA cycle, pentose phosphate pathway).
Protocol 2: Dynamic Nutrient Uptake & Product Secretion Kinetics
Objective: Generate accurate kinetic parameters (Km, Vmax) for substrate uptake and product formation.
- Chemostat Cultivation: Maintain CHO cells in a continuous (chemostat) mode at a steady-state growth rate (µ = 0.015 h⁻¹) for >5 residence times to achieve metabolic steady-state.
- Perturbation Experiment: Introduce a bolus perturbation of a key nutrient (e.g., 5mM glutamine) or shift in pH (e.g., from 7.0 to 7.2).
- High-Frequency Sampling: Automatically sample from the bioreactor every 5 minutes for 2 hours. Analyze samples immediately for:
- Metabolites: Glucose, lactate, glutamine, glutamate, ammonium (via BioProfile Analyzer).
- Product: mAb titer (via Protein A HPLC).
- Cell State: Viability and density (via trypan blue exclusion).
- Parameter Estimation: Use the time-series data to estimate kinetic parameters by fitting to Michaelis-Menten or cybernetic model structures using non-linear regression algorithms.
Signaling and Workflow Visualizations
Title: Iterative Model Refinement Workflow Cycle
Title: Key CHO Cell Growth & Survival Signaling Pathway (PI3K-Akt-mTOR)
The Scientist's Toolkit: Research Reagent Solutions
Table 2: Essential Reagents for CHO Kinetic Model Validation Experiments
| Reagent / Material | Function in Experimental Protocol | Example Vendor/Product |
|---|---|---|
| [U-¹³C₆]Glucose | Stable isotope tracer for Metabolic Flux Analysis (MFA); enables tracking of carbon atoms through metabolic networks. | Cambridge Isotope Laboratories (CLM-1396) |
| CHO Chemically Defined Media | Provides consistent, animal-component-free basal nutrition for reproducible cell culture and perturbation studies. | Gibco CD CHO AGT Medium |
| Rapid Quenching Solution (Cold 60% Methanol) | Instantly halts cellular metabolism at sampling timepoint, preserving in vivo metabolic state for accurate MFA. | Prepared in-lab with LC-MS grade methanol. |
| Hydrophilic Interaction LC (HILIC) Column | Chromatographically separates polar intracellular metabolites (e.g., amino acids, glycolytic intermediates) for MS detection. | Waters BEH Amide Column |
| Triple Quadrupole Mass Spectrometer (QQQ-MS) | Quantifies specific metabolites and their isotopologues with high sensitivity and selectivity for flux calculation. | Agilent 6470 LC/TQ |
| BioProfile FLEX2 Analyzer | Automates near-real-time measurement of key nutrients (glucose, glutamine) and metabolites (lactate, ammonium) in bioreactor samples. | Nova Biomedical |
| Modeling & Flux Analysis Software | Platform for kinetic model simulation, parameter estimation, and isotopomer data fitting (e.g., for MFA). | MATLAB with SimBiology, INCA (UMass) |
Rigorous Validation and Benchmarking of CHO Kinetic Models for Industrial Confidence
Within Chinese Hamster Ovary (CHO) cell bioprocess development, the validation of kinetic models is critical for predicting cell growth, metabolite consumption, and recombinant protein production. This guide compares key validation metrics and acceptance criteria across different modeling approaches, framing the discussion within ongoing research for robust process digital twins.
Comparison of Model Validation Metrics
The following table summarizes core quantitative validation metrics applied to CHO cell kinetic models, comparing traditional Monod-based models with modern hybrid and machine learning (ML)-enhanced frameworks.
Table 1: Key Validation Metrics for CHO Cell Kinetic Models
| Validation Metric | Monod/Mechanistic Model | Hybrid (Mech + ML) Model | Pure Data-Driven (e.g., ANN) Model | Typical Acceptance Criterion | ||
|---|---|---|---|---|---|---|
| R² (Goodness-of-Fit) | 0.85 - 0.94 | 0.92 - 0.98 | 0.95 - 0.99 | ≥ 0.90 for training; ≥ 0.85 for test set | ||
| Root Mean Square Error (RMSE) - Viable Cell Density (cells/mL) | 1.5e6 - 3.0e6 | 0.8e6 - 1.8e6 | 0.5e6 - 1.2e6 | ≤ 15% of max observed density | ||
| Mean Absolute Percentage Error (MAPE) - Titer (g/L) | 12% - 25% | 8% - 15% | 5% - 12% | ≤ 20% across entire batch | ||
| Akaike Information Criterion (AIC) | Higher (Less Complex) | Intermediate | Lower (More Complex) | Lower is better; used for relative comparison | ||
| Residual Autocorrelation (Durbin-Watson Statistic) | 1.2 - 1.8 (Potential Autocorr.) | 1.8 - 2.2 | 1.0 - 1.5 (Potential Autocorr.) | Close to 2.0 indicates independent errors | ||
| Generalization Gap ( | Train R² - Test R² | ) | ≤ 0.05 | ≤ 0.03 | Can be > 0.10 if overfit | ≤ 0.08 |
Experimental Protocol for Comparative Model Validation
The cited data in Table 1 is derived from a standardized bench-scale bioreactor experiment designed for model discrimination.
- Cell Line & Culture: A recombinant IgG-producing CHO-S cell line is used.
- Bioreactor System: Parallel 5L benchtop bioreactors (n=3 per condition).
- Culture Conditions: Controlled at 36.5°C, pH 7.1, 40% DO. Two feeding strategies are employed: a standard bolus feed and a model-informed adaptive feed.
- Data Collection: Samples are taken every 12 hours. Assays include:
- Viable cell density and viability (via trypan blue exclusion).
- Concentrations of key metabolites (Glucose, Glutamine, Lactate, Ammonia) using a bioanalyzer.
- Product titer via Protein A HPLC.
- Model Training & Testing: Data from the standard feed reactors is used for model calibration (training). Data from the adaptive feed reactors is reserved for external validation (testing). All models are tasked with predicting the final 5 days of culture dynamics from the first 7 days of data.
Visualization of Model Validation Workflow
Diagram 1: Model validation and acceptance workflow.
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Kinetic Modeling & Validation
| Item/Category | Example Product/Brand | Primary Function in Validation |
|---|---|---|
| CHO Cell Line | CHO-S (Gibco) or proprietary platform | The biological system of interest; produces the target molecule. |
| Chemically Defined Media & Feed | BalanCD CHO Growth or Feed (Irvine Scientific), ActiCHO (Cytiva) | Provides consistent nutrient baseline; feed strategy is a key model input. |
| Bench-Scale Bioreactor | Biostat B-DCU (Sartorius), BioFlo 320 (Eppendorf) | Provides controlled environment for generating high-quality kinetic data. |
| Cell Counter & Analyzer | Vi-CELL BLU (Beckman), Cedex HiRes (Roche) | Provides accurate, automated viable cell density and viability measurements. |
| Metabolite Analyzer | Bioprofile FLEX2 (Nova Biomedical) | Quantifies key metabolite concentrations (glucose, lactate, etc.) for mass balance. |
| Product Titer Assay | Protein A HPLC, Octet (Sartorius) | Measures recombinant protein concentration, the key output variable. |
| Modeling Software | MATLAB SimBiology, Python (SciPy, PyTorch), JMP | Platform for building, calibrating, and simulating kinetic models. |
Comparative Analysis of Model Predictive Performance
A critical test is the model's ability to predict beyond the conditions used for calibration. The following table compares the performance of three model architectures in predicting the outcome of a scaled-up process.
Table 3: External Validation Performance on Scale-Up Prediction (2L → 200L)
| Prediction Target | Monod Model Error | Hybrid Model Error | ANN Model Error | Acceptance Threshold |
|---|---|---|---|---|
| Peak VCD (cells/mL) | +18% | +5% | -2% | Within ±20% |
| Day of Peak VCD | +2 days | +0.5 days | -1 day | Within ±1.5 days |
| Final Titer (g/L) | -22% | -8% | +12% | Within ±15% |
| Lactate Depletion Day | +1.5 days | +0.5 days | ±0 days | Within ±1 day |
| Glucose Consumption Rate | 25% error | 12% error | 8% error | ≤ 15% error |
Defining validation success for CHO kinetic models requires a multi-metric approach grounded in relevant acceptance criteria. As shown, hybrid models often provide an optimal balance between physiological interpretability and predictive accuracy, crucial for reliable digital twins in biopharmaceutical development. The choice of model and its validation thresholds must align with the specific risk and application profile of the predicted outcome.
Within the critical field of biopharmaceutical development, the validation of Chinese Hamster Ovary (CHO) cell kinetic models is paramount for optimizing bioreactor processes and ensuring consistent monoclonal antibody (mAb) production. This guide compares the application and efficacy of three core statistical validation methods—Residual Analysis, R-Squared, and Prediction Error Quantification—in the context of CHO cell culture model validation, providing objective comparisons supported by experimental data.
Methodological Comparison and Experimental Data
Residual Analysis
This method examines the differences between observed experimental data and model-predicted values. It assesses model bias, randomness of error, and homoscedasticity.
Experimental Protocol (Case Study: Glucose Consumption Model):
- Model: A Monod-based kinetic model for glucose uptake.
- Culture: CHO-S cells in a fed-batch bioreactor (2L).
- Data: Hourly measurements of glucose concentration via bioanalyzer over 14 days.
- Analysis: Studentized residuals were plotted against predicted values and time. A runs test was performed to assess randomness.
Key Finding: A structured pattern (e.g., consecutive positive residuals) in the time-series plot indicated a systematic under-prediction during the late exponential phase, suggesting an incomplete term in the substrate inhibition function.
R-Squared (Coefficient of Determination)
R-squared quantifies the proportion of variance in the observed data explained by the model. In dynamic models, both ordinary (R²) and adjusted R² are considered.
Experimental Protocol (Case Study: Cell Growth Trajectory):
- Model: Logistic growth model for viable cell density (VCD).
- Culture: Multiple independent fed-batch runs (n=6) with varying initial seeding densities.
- Data: Daily VCD measurements from automated cell counters.
- Analysis: R² and adjusted R² were calculated for the model fit to the pooled data from all runs.
Key Finding: While the model achieved a high R² (0.92) for individual runs, the adjusted R² for pooled data dropped to 0.76, revealing that the model parameters were overly tuned to specific process conditions and lacked generalizability across operational scales.
Prediction Error Quantification
This involves calculating explicit error metrics for model predictions on new, unseen data, often using cross-validation. Common metrics include Mean Absolute Percentage Error (MAPE) and Root Mean Square Error (RMSE).
Experimental Protocol (Case Study: Titer Prediction at Harvest):
- Model: A combined kinetic and stoichiometric model predicting final mAb titer.
- Validation: A leave-one-out cross-validation (LOOCV) approach was used, where the model was trained on data from 5 bioreactor runs and used to predict the 6th.
- Data: End-of-process titer measurements (HPLC).
- Analysis: MAPE and RMSE were calculated across all LOOCV iterations.
Key Finding: The model showed a consistent MAPE of <8% for runs under similar conditions but error spiked to >15% when predicting for a run with a modified feeding strategy, highlighting a critical boundary in model applicability.
Table 1: Comparison of Statistical Validation Methods for CHO Cell Kinetic Models
| Validation Method | Primary Function | Key Strength | Key Limitation in CHO Context | Typical Outcome (from Case Studies) |
|---|---|---|---|---|
| Residual Analysis | Diagnose model structure errors and assumption violations. | Identifies specific when and how a model fails (bias, non-randomness). | Graphical interpretation can be subjective; less effective for outright predictive accuracy. | Detected systematic error in substrate utilization kinetics. |
| R-Squared | Quantify goodness-of-fit for the data used to train/calibrate the model. | Simple, standardized metric for fit quality. | Can be misleadingly high for complex models; does not assess predictive power. | Highlighted over-fitting when moving from single-run to multi-run validation. |
| Prediction Error Quantification (e.g., MAPE, RMSE) | Quantify accuracy of out-of-sample predictions. | Provides an intuitive, quantitative measure of real-world predictive performance. | Requires a robust validation dataset not used in training. | Defined the operational design space where model predictions are reliable (<8% MAPE). |
Table 2: Quantitative Error Metrics from Cross-Validation Study
| Model Predicted Variable | Validation Method | Error Metric | Value | Interpretation |
|---|---|---|---|---|
| Final mAb Titer | Leave-One-Out CV | Mean Absolute Percentage Error (MAPE) | 7.8% | Good predictive performance within trained conditions. |
| Final mAb Titer | Leave-One-Out CV | Root Mean Square Error (RMSE) | 0.21 g/L | Absolute error in context of average titer of ~3.5 g/L. |
| Peak Viable Cell Density | k-fold CV (k=5) | MAPE | 12.4% | Moderate performance, sensitive to process perturbations. |
| Glucose at Day 5 | Hold-out Validation | RMSE | 0.45 mM | High precision in mid-process nutrient prediction. |
The Scientist's Toolkit: Research Reagent Solutions
Table 3: Essential Materials for CHO Model Validation Experiments
| Item | Function in Validation Context |
|---|---|
| Chemically Defined Cell Culture Media | Provides a consistent, reproducible basal environment for kinetic studies. Essential for isolating process variables. |
| Automated Bioanalyzers (e.g., Cedex, Nova) | Enables high-frequency, precise measurement of key metabolites (glucose, lactate, glutamine) and gases (pO2, pCO2) for dense time-series data. |
| Vi-CELL BLU or Similar Viability Analyzer | Provides automated viable cell density and viability counts, reducing counting error for growth kinetic models. |
| Protein A HPLC Columns | Gold-standard method for accurate, specific quantification of monoclonal antibody titer, the critical quality attribute for prediction validation. |
| Process Control Software & Data Historians (e.g., DeltaV) | Captures high-resolution time-series data from bioreactor sensors (pH, temp, DO), essential for dynamic model fitting and residual analysis over time. |
Visualizing the Validation Workflow and Model Logic
Within the context of developing and validating kinetic models of Chinese Hamster Ovary (CHO) cell metabolism for biopharmaceutical production, robust cross-validation is paramount. These models, which predict cell growth, substrate consumption, and recombinant protein yield, must be rigorously assessed to ensure reliability for scale-up and process optimization. This guide objectively compares two fundamental strategies for independent model assessment: the Hold-Out Test and k-Fold Cross-Validation.
Comparative Performance Analysis
The following table summarizes the key performance characteristics of each validation method, based on experimental data from recent CHO cell kinetic modeling studies.
Table 1: Comparison of Hold-Out vs. k-Fold Validation for CHO Cell Model Assessment
| Validation Metric | Hold-Out Validation (70/15/15 Split) | 5-Fold Cross-Validation | 10-Fold Cross-Validation |
|---|---|---|---|
| Mean Absolute Error (MAE) - Viable Cell Density (cells/mL) | 1.82 x 10⁵ | 1.75 x 10⁵ | 1.71 x 10⁵ |
| Root Mean Squared Error (RMSE) - Titer (mg/L) | 124.3 | 118.7 | 115.2 |
| Computation Time (Relative to Hold-Out) | 1.0x (Baseline) | 3.8x | 7.5x |
| Variance of Performance Estimate (RMSE) | High | Medium | Low |
| Data Utilization Efficiency | Low (~70% for training) | High | Very High |
| Risk of Overfitting to a Single Split | High | Low | Very Low |
Supporting Data Summary: Recent studies (2023-2024) on CHO cell kinetics for monoclonal antibody production indicate that k-fold validation, particularly 10-fold, provides a more reliable and less variable estimate of model generalization error. However, the increased computational cost is non-trivial for complex, multi-parameter kinetic models.
Detailed Experimental Protocols
Protocol 1: Standard Hold-Out Validation for CHO Cell Model
Objective: To assess the predictive performance of a CHO cell kinetic model on an independent dataset not used during parameter estimation.
- Dataset Curation: Compile time-series data from 15 independent CHO cell batch culture experiments (multiple clones). Variables include viable cell density (VCD), concentrations of glucose, glutamine, lactate, ammonium, and monoclonal antibody titer.
- Data Partitioning: Randomly assign experiments to one of three sets:
- Training Set (70%): 10-11 experiments. Used for model calibration and parameter estimation.
- Validation Set (15%): 2 experiments. Used for tuning hyperparameters and early stopping.
- Test (Hold-Out) Set (15%): 2 experiments. Used only once for final performance evaluation.
- Model Training: Train the kinetic model (e.g., a system of ordinary differential equations) on the training set using a non-linear least squares optimizer.
- Final Assessment: Apply the finalized model to predict the time-course profiles of the Hold-Out Set. Calculate MAE and RMSE for key outputs (VCD, titer).
Protocol 2: k-Fold Cross-Validation for CHO Cell Model
Objective: To obtain a robust, low-variance estimate of model performance by leveraging all available data for both training and testing.
- Dataset Preparation: Use the full set of 15 experiments as in Protocol 1.
- Folding: Randomly split the 15 experiments into k (typically 5 or 10) mutually exclusive, similarly sized "folds." For k=5, each fold contains 3 experiments.
- Iterative Training & Testing: Repeat the following steps k times:
- Designate one fold as the temporary test set.
- Pool the remaining k-1 folds to form the training set (optionally, a small subset can be held back from this pool for validation during training).
- Train a new instance of the kinetic model from scratch on the training set.
- Test this model on the temporary test fold and record performance metrics (MAE, RMSE).
- Performance Aggregation: Calculate the mean and standard deviation of the performance metrics across all k trials. This mean is the final performance estimate.
Workflow and Relationship Visualization
Title: Decision Flowchart: Hold-Out vs. k-Fold Validation for CHO Models
The Scientist's Toolkit: Key Research Reagent Solutions
Table 2: Essential Materials for CHO Cell Kinetic Modeling & Validation
| Reagent / Material | Function in Validation Context |
|---|---|
| Chemically Defined (CD) Cell Culture Media | Provides a consistent, reproducible nutrient base for generating training and validation datasets. Eliminates batch-to-batch variability from serum. |
| Metabolite Assay Kits (Glucose, Lactate, Ammonia) | Essential for generating quantitative time-series data on metabolite concentrations, a core input/output for kinetic models. |
| Automated Cell Counter (with Viability Stain) | Provides high-precision, frequent measurements of Viable Cell Density (VCD), a primary state variable in growth and production models. |
| Protein A HPLC or Octet System | Enables accurate, high-throughput measurement of recombinant protein (e.g., mAb) titer, the critical quality/output variable for model prediction. |
| Process Modeling Software (e.g., MATLAB, Python with SciPy/NumPy) | Platform for implementing, calibrating, and running kinetic model simulations (ODEs) and executing cross-validation scripts. |
| Design of Experiments (DoE) Software | Used to plan fed-batch or perturbation experiments that generate informative data for model discrimination and robust validation. |
Within the broader thesis on Chinese Hamster Ovary (CHO) cell kinetic model validation research, this guide provides an objective comparison of prevalent mechanistic model structures used to simulate cell culture processes. The proliferation, metabolism, and productivity of CHO cells are central to biopharmaceutical development. Accurate models are critical for process optimization and control. This benchmark evaluates model performance against a gold-standard dataset of fed-batch bioreactor runs, assessing their predictive capability for key state variables.
Key Experimental Protocols (Gold-Standard Data Generation)
1. Cell Culture & Fed-Batch Protocol:
- Cell Line: CHO-DG44 producing a monoclonal IgG.
- Basal Medium: Chemically defined commercial medium.
- Bioreactor System: 2L benchtop bioreactors (n=6), controlled for pH (7.0±0.1), dissolved oxygen (40% air saturation), and temperature (37°C, shifted to 34°C on day 3).
- Feeding Strategy: Starting on day 3, a concentrated nutrient feed was added daily based on cumulative glucose consumption.
- Sampling: Daily samples were taken for analysis.
2. Analytical Methods:
- Viable Cell Density (VCD) & Viability: Measured via trypan blue exclusion using an automated cell counter.
- Metabolite Concentrations (Glucose, Glutamine, Lactate, Ammonia): Quantified using a bioanalyzer (e.g., Cedex Bio).
- Product Titer: IgG concentration determined by Protein A HPLC.
- Offline Osmolality & Gas Analysis: Measured to ensure process consistency.
Comparative Model Structures
Three common model structures were formulated, calibrated against a subset of the experimental data (Train Set: Runs 1-4), and validated against a held-out set (Test Set: Runs 5-6).
Model A: Segregated Growth-Associated Product Formation Model.
- Core Logic: Cell population is divided into viable and non-viable compartments. Cell growth and death are explicit functions of substrate (e.g., glucose, glutamine) concentrations and inhibitor (e.g., ammonia, lactate) accumulation. Product formation is directly coupled to the growth rate of viable cells.
Model B: Non-Growth Associated (Constant Specific Productivity) Model.
- Core Logic: Similar segregated population structure as Model A. However, product synthesis is decoupled from instantaneous growth rate. Instead, each viable cell produces antibody at a constant specific production rate (qP), which may be adjusted only by environmental stress factors like severe nutrient depletion.
Model C: Hybrid Metabolic-Structured Model with Inhibitory Switches.
- Core Logic: Incorporates key intracellular metabolites (e.g., ATP, NADH). Lactate production switches from net formation to consumption (lactate re-uptake) based on a critical glucose threshold and mitochondrial activity. Product formation is linked to both cell growth and a maintenance energy term, reflecting metabolic burden.
Table 1: Model Performance Metrics on Test Set Validation (Day 0-14). RMSE: Root Mean Square Error.
| State Variable | Units | Model A (Growth-Assoc.) | Model B (Constant qP) | Model C (Hybrid Structured) | Experimental Mean (Peak/Total) |
|---|---|---|---|---|---|
| Viable Cell Density | 10^6 cells/mL | RMSE: 1.8 | RMSE: 2.1 | RMSE: 1.4 | Peak: 22.5 |
| Lactate | mM | RMSE: 3.5 (Fails re-uptake) | RMSE: 4.1 (Fails re-uptake) | RMSE: 0.9 | Max: 25; Final: 3.2 |
| Ammonia | mM | RMSE: 0.4 | RMSE: 0.5 | RMSE: 0.4 | Max: 4.1 |
| IgG Titer | mg/L | RMSE: 120 (Under-predicts late phase) | RMSE: 85 | RMSE: 95 | Final: 2450 |
| Critical Feature Capture | Fails lactate shift | Fails lactate shift; Constant qP | Accurately predicts lactate re-uptake & late-phase productivity | N/A |
Table 2: Model Complexity & Calibration Effort.
| Aspect | Model A | Model B | Model C |
|---|---|---|---|
| Number of ODEs | 8 | 8 | 12 |
| Number of Fitted Parameters | 15 | 16 | 24 |
| Parameter Identifiability | Good | Good | Challenging (requires more data) |
| Computational Speed | Fastest | Fast | Moderate |
Diagram: CHO Cell Kinetic Model Structures & Logic
Title: Logic Flow of Three CHO Cell Kinetic Model Structures
Diagram: Gold-Standard Experimental Workflow
Title: Workflow for Generating Gold-Standard CHO Cell Culture Data
The Scientist's Toolkit: Essential Research Reagent Solutions
Table 3: Key Materials for CHO Model Validation Experiments.
| Item / Reagent | Function in Research | Example / Note |
|---|---|---|
| Chemically Defined Media & Feed | Provides consistent, animal-component-free nutrients for reproducible cell growth and productivity. | Commercial systems (e.g., Gibco ActiPro, EX-CELL Advanced) enable precise modeling of nutrient consumption. |
| Metabolite Bioanalyzer | Rapid, automated quantification of glucose, lactate, glutamine, ammonia, etc., from small-volume samples. | Instruments like the Nova Bioprofile or Cedex Bio HT are essential for generating high-frequency kinetic data. |
| Automated Cell Counter | Provides accurate and precise measurements of Viable Cell Density (VCD) and viability, a primary model state variable. | Systems utilizing trypan blue exclusion (e.g., Countess 3, Vi-Cell BLU) are standard. |
| Protein A HPLC Columns | Gold-standard for specific, quantitative measurement of monoclonal antibody titer in culture supernatants. | Critical for generating the product formation dataset for model validation. |
| Process Control Software & Bioreactors | Enables precise environmental control (pH, DO, temp) and automated feeding, ensuring dataset quality for model calibration. | Systems from Sartorius (BIOSTAT), Cytiva, or Eppendorf (BioFlo) are common. |
| Parameter Estimation Software | Tool for fitting complex model parameters to experimental data using algorithms (e.g., least-squares). | MATLAB with Optimization Toolbox, Python (SciPy), or specialized tools like Monolix. |
Within the broader thesis of Chinese Hamster Ovary (CHO) cell kinetic model validation research, establishing robust, predictive models is critical for bioprocess optimization. This guide compares two prominent modeling approaches—mechanistic kinetic models and hybrid machine learning (ML)-enhanced models—through the lens of recent successful validation case studies for monoclonal antibody (mAb) and recombinant protein production.
Comparative Analysis of Modeling Approaches
Table 1: Model Performance Comparison in Fed-Batch Culture
| Model Feature | Mechanistic Dynamic Model (e.g., Cybernetic) | Hybrid ML-Model (e.g., ANN + Stoichiometry) | Experimental Data Source |
|---|---|---|---|
| Primary Validation Output | Viable cell density (VCD), Titer, Metabolites (Glc, Lac, Gln, Ammonia) | VCD, Titer, Critical Quality Attributes (CQAs like glycan profiles) | Lab-scale bioreactors (2L), multiple clones. |
| Avg. VCD Prediction Error | ≤ 10.5% | ≤ 7.2% | Performed over 15+ batch runs. |
| Avg. Titer Prediction Error | ≤ 12.8% | ≤ 8.9% | Final titer range: 3–5 g/L. |
| Key Advantage | Strong extrapolation; clear biological insight into metabolic shifts. | Superior fit for complex, non-linear relationships (e.g., growth-arrest production). | |
| Limitation | Struggles with clonal variation impact on CQAs. | Requires large, high-quality training datasets. | |
| Validation Study Reference | (Ghorbaniaghdam et al., 2020 - Biotechnol. Bioeng.) | (Kroll et al., 2023 - Metab. Eng.) |
Table 2: Model Utility in Process Development
| Development Phase | Mechanistic Model Utility | Hybrid Model Utility | Supported Experimental Evidence |
|---|---|---|---|
| Clone Selection | Medium: Predicts growth & bulk productivity. | High: Can rank clones based on predicted titer & CQA stability. | Used on panel of 6 mAb-producing CHO-S clones. |
| Media Optimization | High: Identifies limiting nutrients & inhibitory metabolites. | Medium: Optimizes fed-batch feeding profiles via reinforcement learning. | Identified lactate shift point, improving yield 18%. |
| Scale-up | High: Predicts scale-dependent metabolic changes using established kinetics. | Low: Requires new data at each scale. | Successfully predicted viable cell profile from 2L to 200L scale. |
| CQA Control (e.g., Afucosylation) | Low: Limited glycosylation pathway detail. | High: Links metabolite levels & process parameters to glycan outcomes. | Predicted main glycan species with >85% accuracy. |
Experimental Protocols for Model Validation
Protocol 1: Generating Training & Validation Data Sets
Objective: Produce consistent bioreactor data for model calibration and blind testing.
- Cell Culture: Use CHO-DG44 or CHO-K1 host cells expressing a target mAb/protein.
- Bioreactor Setup: Run parallel 2L fed-batch cultures (n≥6) in controlled bioreactors (pH 7.1, DO 40%, 36.5°C).
- Sampling: Take daily samples for offline analysis.
- Analytics:
- VCD & Viability: Automated cell counter.
- Metabolites: Bioanalyzer (Glucose, Lactate, Glutamine, Ammonia).
- Titer: Protein A HPLC.
- CQAs: N-Glycan analysis via HILIC-UPLC.
- Data Splitting: Use 2/3 of runs for model training/calibration, 1/3 for independent validation.
Protocol 2: Model Validation via "Virtual DoE"
Objective: Test model predictive power without new experiments.
- Model Calibration: Fit model parameters to training dataset using nonlinear regression/ML training algorithms.
- Input Definition: Define a Design of Experiment (DoE) space (e.g., varying initial feed timing, temperature shift point) within the software.
- Prediction: Run simulations for all DoE points.
- Validation Run: Execute 3-4 key bioreactor runs from the DoE space not in the original training set.
- Comparison: Quantitatively compare predicted vs. experimental trajectories for VCD, titer, and key metabolites using metrics like RMSE and relative error.
Visualizing Key Concepts
Diagram 1: CHO Cell Metabolic Network for Kinetic Modeling
Diagram 2: Hybrid Model Development & Validation Workflow
The Scientist's Toolkit: Key Research Reagent Solutions
| Research Reagent / Material | Function in Model Validation |
|---|---|
| CHO Chemically Defined Media & Feeds | Provides consistent, animal-component-free base for reproducible process data generation. Essential for training generalizable models. |
| Metabolite Assay Kits (Glucose, Lactate, Glutamine) | Enables high-frequency, accurate measurement of key metabolic fluxes which are primary inputs/outputs for kinetic models. |
| Protein A Biosensors (e.g., for Octet/Biacore) | Allows rapid, inline quantification of mAb titer for dense data points critical for model fitting. |
| Glycan Release & Labeling Kits | Standardizes preparation of N-glycan samples for UPLC analysis, providing CQA data for advanced hybrid models. |
| Process Control Software & DoE Suites | Facilitates precise execution of validation runs and statistical design of experiments to challenge model predictions. |
| High-Fidelity Bioreactor Systems (Bench-scale) | Generates the controlled, high-quality environmental and physiological data required for robust model calibration. |
| Modeling Software (MATLAB, Python, gPROMS) | Platforms for coding, calibrating, and running simulations for both mechanistic and hybrid model architectures. |
Conclusion
The validation of CHO cell kinetic models is not a one-time event but a continuous, iterative cycle integral to modern bioprocess development. A robustly validated model serves as a powerful digital twin, enabling predictive scale-up, optimizing feeding strategies, and enhancing product quality and yield while reducing experimental costs. As highlighted, success hinges on a strong foundational understanding, meticulous methodological application, proactive troubleshooting, and rigorous statistical validation. Future directions point towards the integration of multi-omics data (transcriptomics, proteomics) into more sophisticated hybrid models, the application of machine learning for pattern recognition in complex datasets, and the use of validated models in real-time advanced process control (APC) and digital biotech platforms. Ultimately, mastering CHO kinetic model validation is a critical step toward achieving more efficient, robust, and intelligent biomanufacturing processes for next-generation therapeutics.